

지금 참여하고 있는 인프라 스터디에서 책도 보고 있지만 동시에 CNCF에서 지원하는 프로젝트도 하나씩 살펴보고 있다. 돌아가면서 공부해서 발표하는 방식이라 이번에 Cortex라는 프로젝트를 살펴봤다.
Cortex란?
Cortex는 현재 CNCF의 Sandbox 프로젝트로 작년(2018년) 9월에 Sandbox 프로젝트가 되었으니 얼마 되지 않았다. CNCF는 Sandbox - Incubating - Graduated 순으로 진행되므로 Sandbox는 초기 단계라고 할 수 있다. 그래서인지 공식 문서와 자료가 많지 않아서 공부하는데, 시간이 걸렸다. Cortex를 자세히 보진 못했고 간단히 어떤 구조로 되어있어 어떤 역할을 하는 프로젝트 인지만 파악해 봤다.
스터디 전에는 Cortex를 전혀 모르고 있었는데 Cortex를 선택한 것은 (내가 관심 있는 굵직굵직한 프로젝트는 이미 다른 분들이 선점해서이기도 하지만...) 최근에 Prometheus 식으로 로그를 수집하는 Loki를 살펴보고 싶었는데 Loki가 Cortex에서 파생된 프로젝트라고 나와 있었기 때문이다. Loki는 아직 CNCF 프로젝트가 아니기도 했고 그래서 Cortex는 무슨 프로젝트지? 하는 궁금함에 보기 시작했다.

Cortex 저장소에 가면 Prometheus-as-a-Service라고 설명하고 있다. 즉, Prometheus를 서비스로 제공하기 위한 프로젝트라는 의미이다.
Cortex provides horizontally scalable, multi-tenant, long term storage for Prometheus metrics when used as a remote write destination, and a horizontally scalable, Prometheus-compatible query API.
위는 좀 더 자세한 설명인데 그 의미를 풀어보면 Prometheus가 보통 한 서버에서 메트릭을 저장하게 되어 있고 샤딩 기반의 확장만 지원하는데, Cortex를 쓰면 수평적 확장을 지원하고 단기간만 메트릭을 저장하는 게 아니라 롱텀 스토리지로 데이터를 오랫동안 보관하고 멀티 테넌트, 즉 여러 서비스나 사용자가 메트릭을 따로 저장하고 관리할 수 있도록 한다는 뜻이다. 저장뿐 아니라 Prometheus 호환 쿼리 API를 지원하므로 수평적 확장을 통해서 메트릭을 읽어오는 것도 가능하다.
What is Cortex?를 보면 자세한 히스토리가 나오는데 weaveworks에서 Kubernetes로 Prometheus를 운영하고 있었는데 Persistent Volume은 사용하지 않아서 재배포할 때마다 데이터가 사라지는 상황이었다. 메트릭이 보통 최근 데이터만 있으면 되므로 처음에는 큰 문제가 안 되다가 이 문제를 해결하려고 Persistent Volume를 고려하다가 고객마다 Prometheus 인스턴스를 운영하고 싶지 않아서 Prometheus-as-a-service로 가기로 하고 수평적 확장을 지원하도록 Cortex를 만들게 되었다. Cortex의 설계는 Amazon Dynamo 논문에 영향을 크게 받았다고 한다.
Prometheus의 remote_write를 이용해서 Prometheus에서 Cortex로 메트릭을 보내서 저장하는 방식이다. 이 remote_write는 Cortex를 만든 Tom Wilkie와 Julius Volz가 Prometheus에 추가했다.
Cortex 아키텍처
아키텍처 문서를 보면 대략적인 구조를 이해할 수 있다.
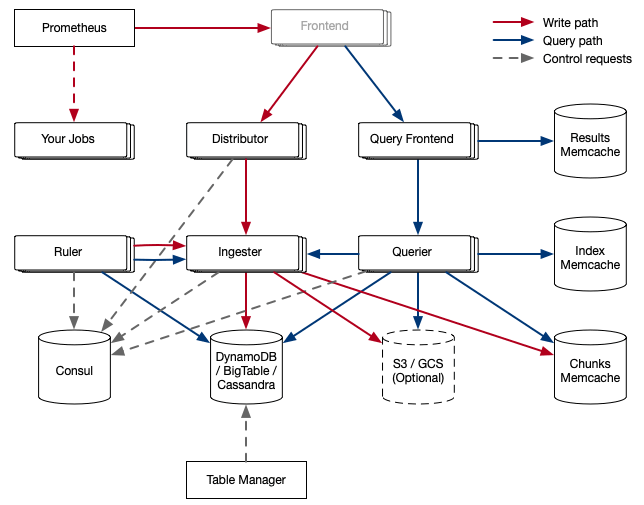
위 구조에서 Prometheus와 Your Jobs라고 된 부분은 Cortex의 구조에는 안 들어간다. 메트릭을 수집한 Promethues에서 remote_write로 Cortex에 메트릭을 보내는 것을 나타낸 것이다. Frontend라고 된 부분은 회색으로 음역처리가 되어 있는데 Cortex를 좀 띄워 봤을 때는 Cortex 자체의 구성 요소라기보다는 앞에서 nginx같은 웹서버로 라우팅하므로 진입점이라는 의미로 그린 것 같다.
각 구성 요소를 살펴보자. 위 그림과 각 구성 요소의 역할을 같이 보면 이해하기가 좀 쉽다.
- Prometheus
- 메트릭을 수집해서 Cortex에 넣는 역할을 하는데 이때 remote write API를 사용한다.
- remote write API는 Snappy로 압축된 Protocol Buffer 메시지를 HTTP PUT 요청을 배치로 사용한다.
- 쓰기 요청은 Distributor가 받고 PromQL 쿼리를 이용한 읽기 요청은 Query Frontend가 받는다.
- Distributor
- Prometheus가 보낸 메트릭을 처리하고 gRPC로 ingester와 통신한다.
- 상태가 없으므로 필요에 따라 확장할 수 있다.
- consistent hash ring를 이용해서 어떤 ingester가 메트릭 데이터를 받을지를 결정하고 이 consistent hash ring은 Consul에 저장된다.
- hash ring 데이터 구조를 Protobuf 메시지로 인코딩된다.
- Ingester
- DynamoDB, BigTable, S3, Cassandra 같은 롱텀 스토리지 백엔드에 데이터를 저장하는 역할을 한다.
- Ingester는 아무것도 공유하지 않고 데이터를 처리한다.(shared-noting process)
- 약간의 상태를 가지는데 최신 12시간의 메트릭을 유지하고 있으므로 재시작할 때는 데이터를 잃지 않게 조심해야 한다.
- Ruler
- alertmanager가 만든 알림을 다룬다.(이번에 살펴볼 때는 자세히 보지 않았다.)
- Query Frontend
- Query Frontend는 PromQL로 remote_read를 사용할 때만 띄우면 되고 Cortex 구성에서 반드시 띄워야 하는 것은 아니다.
- Queuing을 통해 실제 쿼리를 실행하는 Querier가 대형 쿼리를 실행하다가 Out Of Memory를 일으킬 때를 위해 재시도를 보장하고 쿼리를 FIFO로 분산해서 한 Querier가 대형 쿼리를 다수 받지 않도록 하며 서비스 사용자(tenant)가 쿼리를 공정하게 스케줄링해서 DoS에서 사용자를 보호한다.
- Splitting을 통해 여러 날짜에 걸치 쿼리를 하루짜리 다수의 쿼리로 나누어서 Querier로 보내고 결과를 받아서 다시 합친다.
- 쿼리 결과를 캐싱하고 이를 재사용한다.
- Querier
- 롱텀 스토리지에 저장된 데이터에서 실제 PromQL 평가를 처리한다.
- Chunk Store
- Cortex의 롱텀 데이터 스토어다.
- Cortex의 롱텀 데이터 스토어다.
데모 실행
프로젝트가 아직 많이 성숙하지 않아서인지 Cortex가 호스팅을 하기 위한 프로젝트라서 인지 프로덕션 설치 문서는 발견하지 못했다. 호스팅이 아니더라도 큰 조직에서는 Cortex가 필요한 때도 있을 것 같은데 저 복잡한 구성을 프로덕션에서는 어떻게 설정해야 하는지는 잘 모르겠다.(자기네 호스팅 서비스 쓰라고?) 대신 개발용으로 Kuberntes로 쉽게 Cortex 환경을 구성할 수 있도록 제공하고 있어서 간단히 실행해 볼 수 있었다.
Cortex 저장소를 클론 받으면 실행해 볼 수 있도록 k8s 디렉터리가 있다. 이 Kubernetes 설정에서 사용하는 이미지는 Quay의 이미지를 사용하는데 지정된 latest 이미지는 없으므로 로컬에서 생성해야 한다. 저장소를 클론 받아서 make 명령어를 실행하면 로컬에 이미지가 만들어진다.
$ kubectl create -f ./k8s
deployment.extensions "alertmanager" created
service "alertmanager" created
deployment.extensions "configs-db" created
service "configs-db" created
deployment.extensions "configs" created
service "configs" created
deployment.extensions "consul" created
service "consul" created
deployment.extensions "distributor" created
service "distributor" created
deployment.extensions "dynamodb" created
service "dynamodb" created
deployment.extensions "ingester" created
service "ingester" created
deployment.extensions "memcached" created
service "memcached" created
configmap "nginx" created
deployment.extensions "nginx" created
service "nginx" created
deployment.extensions "querier" created
service "querier" created
deployment.extensions "query-frontend" created
service "query-frontend" created
configmap "retrieval-config" created
deployment.extensions "retrieval" created
service "retrieval" created
deployment.extensions "ruler" created
service "ruler" created
deployment.extensions "s3" created
service "s3" created
deployment.extensions "table-manager" created
service "table-manager" created
이는 Cortex 개발용 환경으로 필요한 모든 구성이 실행된다.(앞에서 말했듯이 프로덕션용 설정 문서는 찾지 못했다.)
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/alertmanager-54d9cfd844-z7jnv 1/1 Running 0 7m
pod/configs-84ff5785c-9kldc 1/1 Running 0 7m
pod/configs-db-5f9b64f5cc-wwx48 1/1 Running 0 7m
pod/consul-5c4f79cf47-flmsb 1/1 Running 0 7m
pod/distributor-6b58d9986-hv5nj 1/1 Running 0 7m
pod/dynamodb-68fc4457c6-9c7pq 1/1 Running 0 7m
pod/ingester-7b7b9f8f84-2dftc 1/1 Running 0 7m
pod/memcached-f99cdf957-cdgbq 1/1 Running 0 7m
pod/nginx-7856cc488b-vnk4l 1/1 Running 1 7m
pod/querier-58646d4dc9-vsrg8 1/1 Running 0 7m
pod/query-frontend-59dbb8dd95-x29sg 1/1 Running 0 7m
pod/retrieval-69bd8bdd88-xwc9d 1/1 Running 0 7m
pod/ruler-6fbbb9998b-vdjhg 1/1 Running 0 7m
pod/s3-57dc56ffb4-tl2hp 1/1 Running 0 7m
pod/table-manager-5b474f6685-ll5l8 1/1 Running 0 7m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager ClusterIP 10.99.21.8 <none> 80/TCP 7m
service/configs ClusterIP 10.109.200.199 <none> 80/TCP 7m
service/configs-db ClusterIP 10.108.43.242 <none> 5432/TCP 7m
service/consul ClusterIP 10.104.52.73 <none> 8500/TCP 7m
service/distributor ClusterIP 10.102.76.244 <none> 80/TCP 7m
service/dynamodb ClusterIP 10.101.128.11 <none> 8000/TCP 7m
service/ingester ClusterIP 10.109.232.228 <none> 80/TCP 7m
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d
service/memcached ClusterIP None <none> 11211/TCP,9150/TCP 7m
service/nginx NodePort 10.100.221.142 <none> 80:30080/TCP 7m
service/querier ClusterIP 10.97.68.116 <none> 80/TCP 7m
service/query-frontend ClusterIP None <none> 9095/TCP,80/TCP 7m
service/retrieval ClusterIP 10.102.125.39 <none> 80/TCP 7m
service/ruler ClusterIP 10.111.194.194 <none> 80/TCP 7m
service/s3 ClusterIP 10.102.240.155 <none> 4569/TCP 7m
service/table-manager ClusterIP 10.107.78.253 <none> 80/TCP 7m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/alertmanager 1 1 1 1 7m
deployment.apps/configs 1 1 1 1 7m
deployment.apps/configs-db 1 1 1 1 7m
deployment.apps/consul 1 1 1 1 7m
deployment.apps/distributor 1 1 1 1 7m
deployment.apps/dynamodb 1 1 1 1 7m
deployment.apps/ingester 1 1 1 0 7m
deployment.apps/memcached 1 1 1 1 7m
deployment.apps/nginx 1 1 1 1 7m
deployment.apps/querier 1 1 1 1 7m
deployment.apps/query-frontend 1 1 1 1 7m
deployment.apps/retrieval 1 1 1 1 7m
deployment.apps/ruler 1 1 1 1 7m
deployment.apps/s3 1 1 1 1 7m
deployment.apps/table-manager 1 1 1 1 7m
NAME DESIRED CURRENT READY AGE
replicaset.apps/alertmanager-54d9cfd844 1 1 1 7m
replicaset.apps/configs-84ff5785c 1 1 1 7m
replicaset.apps/configs-db-5f9b64f5cc 1 1 1 7m
replicaset.apps/consul-5c4f79cf47 1 1 1 7m
replicaset.apps/distributor-6b58d9986 1 1 1 7m
replicaset.apps/dynamodb-68fc4457c6 1 1 1 7m
replicaset.apps/ingester-7b7b9f8f84 1 1 1 7m
replicaset.apps/memcached-f99cdf957 1 1 1 7m
replicaset.apps/nginx-7856cc488b 1 1 1 7m
replicaset.apps/querier-58646d4dc9 1 1 1 7m
replicaset.apps/query-frontend-59dbb8dd95 1 1 1 7m
replicaset.apps/retrieval-69bd8bdd88 1 1 1 7m
replicaset.apps/ruler-6fbbb9998b 1 1 1 7m
replicaset.apps/s3-57dc56ffb4 1 1 1 7m
replicaset.apps/table-manager-5b474f6685 1 1 1 7m
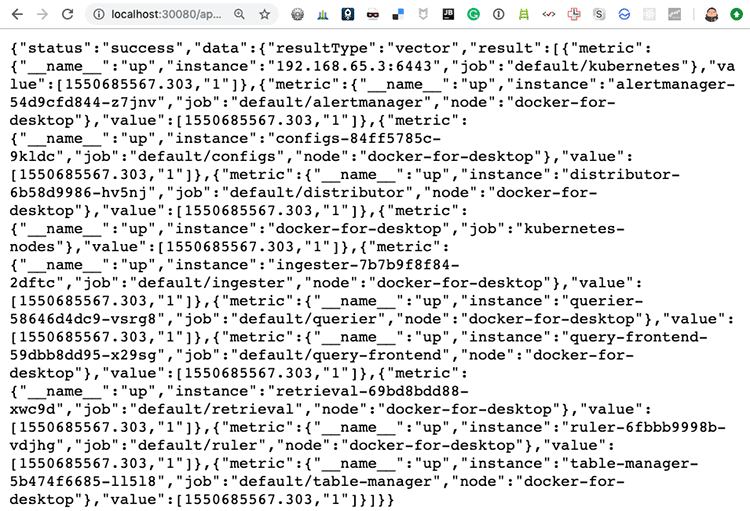
개발용이라 상당히 많은 서비스가 실행된다. 앞에 아키텍처 구성과 같이 보면 어떤 서비스가 실행되었는지 알 수 있고 dynamodb나 s3 같은 건 로컬에서 테스트해볼 수 있는 이미지들이다. http://localhost:30080/api/prom/api/v1/query?query=up에 접속해 보면 Query Frontend에 접속해서 PromQL 쿼리를 실행해 볼 수 있다. 여기서는 Cortex에서 실행된 서버(up)를 조회한 것이다.
여기에 Grafana를 연동해서 확인해 볼 수 있는데 Cortex에서 Grafana의 대시보드 설정을 생성할 수 있도록 이미 제공하고 있다. 로컬에 데이터 템플릿 언어인 Jsonnet을 설치하고 Grafonnet을 클론 받는다. 앞에서 클론 받은 Cortex 디렉터리에서 docs/dashboards에 들어가서 아래 명령어를 실행한다.
$ jsonnet -J ../../grafonnet-lib/ -o cortex-read.json cortex-read.jsonnet
$ jsonnet -J ../../grafonnet-lib/ -o cortex-write.json cortex-write.jsonnet
여기서 ../../grafonnet-lib/는 앞에서 Grafonnet을 클론 받은 디렉터리의 위치이다. 이 두 명령어를 실행하면 cortex-read.json, cortex-write.json 파일이 생성된다. 이 파일은 Grafana 대시보드에서 불러올 수 있는 설정 파일이라고 생각하는데 Jsonnet을 처음 써봐서 자세한 파일의 내용은 모르는 상태이다.
$ docker run -d -p 3000:3000 grafana/grafana
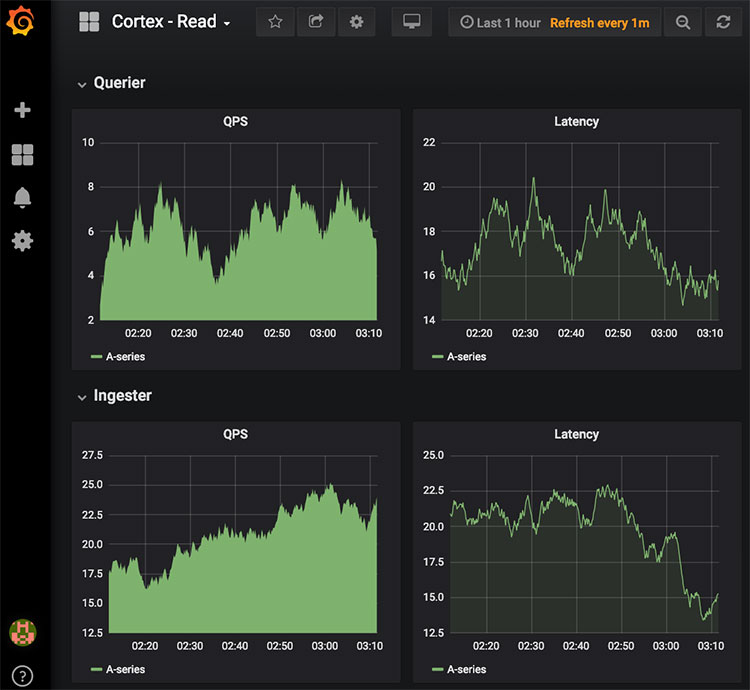
위 명령어로 Grafana를 실행하고 http://localhost:3000에 접속하면 Grafana에 접속할 수 있다.(초기 로그인 정보는 admin/admin이다.) 접속한 후 Import로 앞에서 생성한 cortex-read.json, cortex-write.json를 불러오면 다음과 같이 바로 대시보드가 생성되고 Cortex의 매트릭을 볼 수 있다. 이 JSON 파일의 구조까지는 몰라서 바로 실행했는데 이전 시간의 매트릭정보까지 나오는 이유는 잘 모르겠다. 여기서는 Cortext의 동작을 보는 것이므로 그냥 넘어갔다.
k8s/nginx-config.yaml 파일의 내용을 보면 Cortex가 정보를 받는 라우팅 경로를 볼 수 있다.
location = /api/prom/push {
proxy_pass http://distributor.default.svc.cluster.local$request_uri;
}
location ~ /api/prom/.* {
proxy_pass http://query-frontend.default.svc.cluster.local$request_uri;
}
/api/prom/push는 메트릭을 저장하는 Distributor로 보내는 경로이고 그 외 /api/prom/.*로 들어오는 요청은 Query Frontend로 전달된다.
이제 Cortex를 실행했는데 Cortex 자체가 Prometheus의 매트릭을 저장하는 역할이므로 Prometheus가 있어야 동작 여부를 제대로 확인할 수 있다. 다음과 같이 prometheus.yml 설정 파일을 생성한다. 이는 기본적인 Promethus 설정 파일이다.
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# Settings related to the remote write feature.
remote_write:
- url: "http://localhost:30080/api/prom/push"
맨 마지막을 보면 remote_write에서 Cortext에 원격 쓰기를 하도록 설정한 것을 볼 수 있다.
$ ./prometheus --config.file=prometheus.yml
Prometheus를 로컬에 설치하고 위의 설정 파일로 실행하면 http://localhost:9090에 접속해서 확인해 볼 수 있다. remote_write를 설정했으므로 다시 Cortex의 Query Frontend인 http://localhost:30080/api/prom/api/v1/query?query=up에 접속해서 확인해 보면 방금 실행한 http://localhost:9090가 추가된 것을 볼 수 있다. 이는 앞에서 실행했을 때는 없던 메트릭 정보이다.
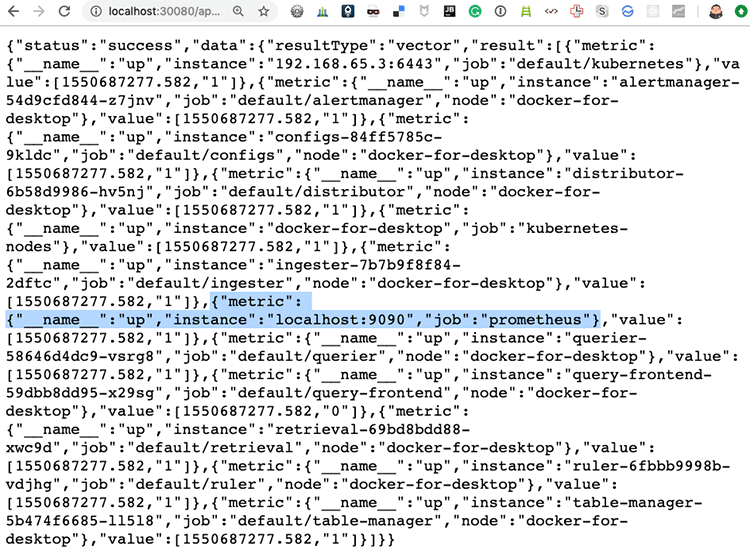
동작을 다시 설명하면 Prometheus가 자신이 수집한 메트릭 정보를 remote_write로 Cortex에 저장하고 이를 조회한 것이다.
앞에서 작성한 prometheus.yml 파일에 아래의 remote_read 설정을 추가해 보자.
# Settings related to the remote read feature.
remote_read:
- url: "http://localhost:30080/api/prom/read"
read_recent: true
이 설정으로 Prometheus를 다시 실행하고 http://localhost:9090에 접속해서 up 인스턴스를 조회하면 다음과 같이 Prometheus뿐만 아니라 Cortex에 저장되어 있던 메트릭 정보도 같이 조회되는 것을 확인할 수 있다.
앞에서 설명한 데로 remote_write로 메트릭을 Cortex에 장기로 저장해서 사용할 수도 있는데 Prometheus에서 메트릭 정보를 너무 많이 저장해서 보관할 수는 없으므로 Cortex를 remote_read로 설정하면 Prometheus에서 조회할 때도 Cortex의 정보를 같이 조회해서 보여준다.
이렇게 설정해서 사용한다면 Prometheus에는 필요한 짧은 기간의 메트릭 정보만 보관하면서 사용하다가 긴 기간의 데이터를 조회할 때는 Cortex에서 불러오도록 해서 사용할 수 있다.

Comments