

자바 커뮤니티 공동 세미나 "자바 개발자를 위한 ‘共感(공감)’을 찾아서" #1
Adobe에서 진행한 "자바 개발자를 위한 ‘共感(공감)’을 찾아서"세미나 에 갔다가 왔습니다. 세미나 주제들이 괜찮아 보여서 바로 신청하기는 했었지만 약간은 의외의 컨셉의 세미나였습니다. 이번행사는 OKJSP, JBoss User Group, KSUG 가 공동주최하고 Adobe 에서 후원하였는데 처음 세미나 공지를 보았을때 "왜? 어도비가 자바세미나를?"이라는 생각이 들더군요. BlazeDS 때문인가 싶기도 했는데 딱히 그런 언급은 없었습니다. 머 의도야 어쨌든 이렇게 좋은 세미나를 무료로 진행해 주니 감사한 마음에 갔다가 왔습니다.


자바와 Flex의 만남 - Adobe Community Champion 엄진영( 블로그)
부재로는 "스프링과 연동한 BlazeDS 활용"이라는 이름이 붙어있었습니다만 실제로는 Blaze에 대한 언급은 거의 없었습니다. 개발의 기술발전의 히스토리들(주로는 엄진영님이 접하게 된 시점위주로)을 설명하면서 RIA가 플래시가 왜 필요한가에 내용이었습니다.
Flex는 이제 Flash라는 이름으로 통일이 되고 있습니다. 그동안은 Flex라는 개념의 혼동때문에 Flash와 Flex의구분을 고객들에게 설명하기 위해서 어려움들이 있었지만 이젠 모두 Flash로 통일되고 있고 Flex builder도 Flash Builder 4 로 변경이 되었습니다. 서버사이드는 보통 자바가 많이 쓰이고 기술과 트랜드는 계속 바뀌고 있습니다. 과거 프로그램을 자주 변경해야 되는 상황이 생기면서 그동안 사용하던 C언어보다는 스크립트 언어를 선호하게 되었지만 곧 만들어야 하는 프로그램의 크기가 커지면서 스크립트 언어로써의 한계에 부딪히게 됩니다. 스펙을 정해놓고 사용하게 되는 엔터프라이즈로 넘어가게 되었는데 실제 개발은 서버보다는 UI를 많드는데 훨씬 많은 시간이 소비되게 되었습니다.



그래서 프로세스의 혁신이 필요해지게 됩니다. 프로세스의 혁신이란 것은 야근등으로 개발자의 능력치를 최대한 끌어냈으나(엄진영님은 "이미 쪽쪽 빨아서"라고 표현을ㅎㅎ) 더이상 끌어낼수 없을때 필요해 지는 것입니다. 초보개발자도(싸니까) 만들수 없을까? 하는 고민을 하면서 프레임워크로 초점이 넘어가고 그후에는 퍼시스턴스에 관심을 가지게 됩니다. 2007년부터 UI에 대한 고민을 시작하게 되고 그전에는 브라우저전쟁에서 승리한 IE에 맞춰서 개발하다가 브라우져마다 약간씩 다르기 때문에 다른 브라우저에 맞추는 추가적인 작업을 하게 됩니다. 국내시장에서는 깔끔하게 IE외의 브라우져는 포기해버렸습니다.
이 상황에 Ajax도 등장하여 서버에 직접 접근하게 되고 엔터프라이즈급 UI를 Javascript만으로 하는 것이 개발자에게 너무 힘든 일이 되어버립니다. 그래서 Needs에 따라 쓰는 방식은 그대로 유지하면서 Flash를 위한 Flex가 등장하게 됩니다.
RIA의 장점은 플랫폼 독립적이고(자바도 목적은 그랬지만 현실적으로 그러지 못했습니다.) 기존 기술과 유사하여 배우기가 용이하면서 대규모 시스템 개발이 가능하다는 것이었습니다. 그리고 가장 중요한 것은 UI부분이 서버와 투명하게 분리가 가능하게 된 것이었습니다. Ajax덕분에 클라이언트가 서버에 직접 접속하게 되면서 서버에 종속적으로 묶여버렸습니다. 플래시앱(.swf)는 서버와 HTTP 원격객체호출을 할수 있고 HTTP 서비스, 메시징 서비스, 웹서비스를 할수 있으며 Ajax에 비해 binary 데이터를 주고 받을 수 있다는 큰 장점도 있습니다.
히스토리야 어느정도 알고 있는 내용이니 공감은 하고 있었지만 Flash Platform에 대한 당위성에 대한 공감은 좀 약하지 않았나 싶습니다. 여러 연구들과 프레임워크들의 등장으로 인하여 UI가 서버에 종속된다는 것은 공감이 잘 안되기도 했고 (기술적이든 사용상의 문제이든 간에)실제 플래시를 사용하는데에 대한 trade off가 존재하는 것은 사실이라고 생각하고 있습니다. Flash가 등장한 이래 가장 큰 위기감을 최근 느끼고 있다고 생각하는데 Flash가 통짜로 올라가면 화려하긴 진짜 화려하긴 하지만 무겁기도 하고 그렇게 화려할 필요가 있는가에 대한 고민도 하게 되죠.
Apache Hadoop으로 구현하는 상품추천서비스 - JBoss User Group 김병곤
추천검색은 은근히 여기저기 많이 쓰이고 있습니다. 메론, Amazon, 네이버 인물 검색등 알게 모르게 추천검색이 다 적용되어 있습니다. 실제로 추천검색을 적용해 보면 30%정도가 구입을 하는데 이는 엄청난 적중률입니다. 추천시스템을 구현하는 방법에는 사용자로부터 얻은 기호정보를 토대로 예측하는 협업필터링(Collaborating Filtering), 상품간의 연관성을 분석하여 다른 사용자에게 구매하지 않은 상품을 추천하는 연관규칙(Association Rule), 비슷한 대상들끼리 묶은 군집을 이용하는 클러스터링(Clustering)등이 있습니다.
웹2.0의 많은 서비스들이 추천시스템을 사용하고 있고 우리가 하는 모든 행동은 로그가 남고 있고 우리는 엄청난 데이터 속에서 살고 있으며 이 엄청난 데이터는 Hadoop 이 아니면 다룰 수가 없습니다. 데이터가 너무 엄청나기 때문에 데이터베이스로 다룰려면 데이터를 데이터베이스롤 올리는데 시간이 다 가버릴 정도입니다.
패러다임의 전환이 필요합니다.
로직이 데이터에 접근하지 말고 데이터가 있는 곳으로 로직을 옮겨라!
데이터가 쪼개지고 로직도 각 데이터로 분산된 다음에 합칩니다.
왜 데이터베이스가 적합하지 않은가 하면 대용량 파일은 Import하는 것도 어렵고 리소스소비가 심하여 온라인 작업과 배치작업을 분리해야 하는 문제가 있습니다. 그리고 비싼 장비와 SW비용이 필요합니다. 대신 대용량에 Apache Hadoop가 적합한 이유는 로그정보가 수십Tera에 이를 정도로 매우 크고 I/O집중적이면서 CPU도 많이 사용하는 작업입니다. 또한 장비를 증가시킬수록 성능은 향상되고 Intel Core머신은 가격이 아주 쌉니다. 인텔컴퓨터 하나 사서 추가하면 용량이 늘어나기 때문에 개발자는 관리가 힘들어지더라도 운영자입장에서는 당연히 하둡을 선택하게 됩니다. 이런 것을 보면서 이제 데이터베이스는 사라지는 것이 아니냐고도 하는데 Hadoop은 데이터베이스를 대체할 기술이 아니라 공존할 기술입니다.




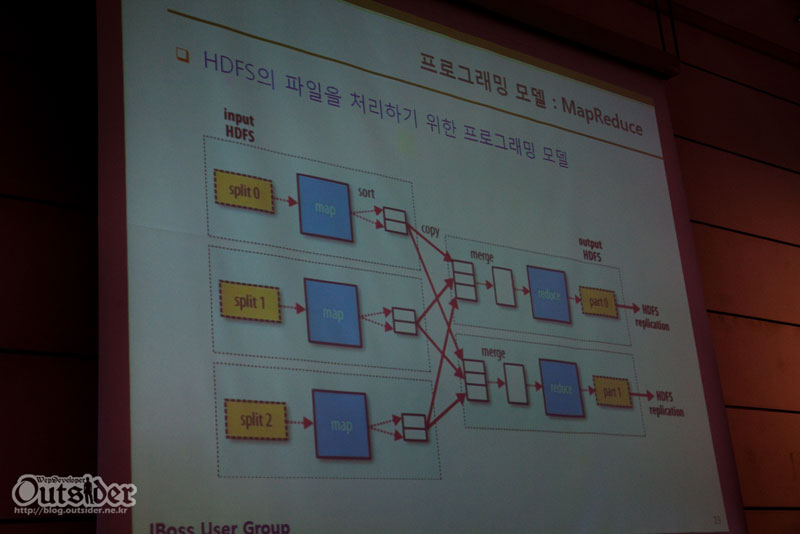
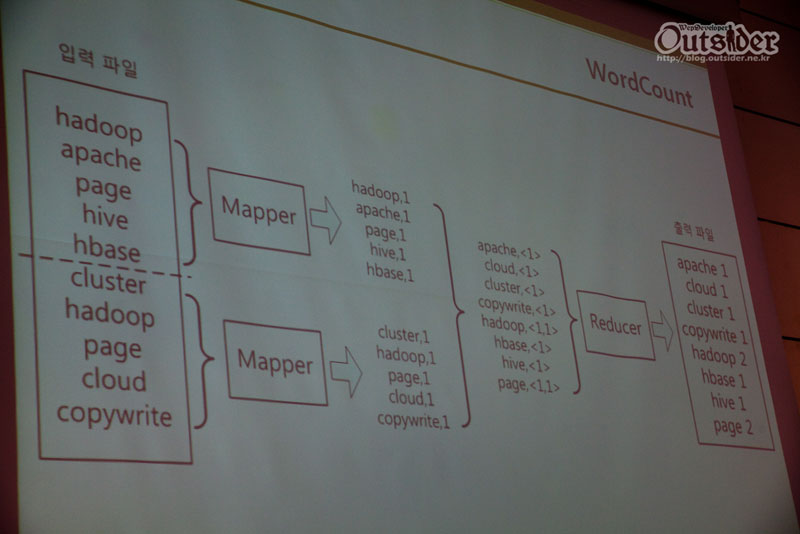
Hadoop은 "파일을 올리는 것"과 "처리하는 것" 딱 이 2가지가 전부입니다. 즉 File System(HDFS:Hadoop Distributed File System)과 프로그래밍모델(MapReduce)입니다. HDFS는 파일을 64M단위로 나누어 장비에 저장하는 방식이고 사용자에게는 하나의 파일로 보이지만 실제로는 나누어져 있습니다. MapReduce는 HDFS의 파일을 이용하여 처리하는 방법을 제공합니다.
나누어서 처리할 때의 가장 큰 문제는 합치는 것이고 대표적인 것이 소팅입니다. 맵과 리듀스의 개념을 이해하는 것이 코딩보다도 더 중요합니다. Hadoop은 무조건 Key - Value의 데이터 구조 이 한가지 밖에 없습니다. 이 Key - Value로 된 데이터들이 합쳐지면서 같은 Key의 Value는 배열로 묶어줍니다.
연관 규칙(Association Rule)의 예로 간단한 마켓의 상품으로 추천시스템을 적용하는 예를 보여주셨습니다. 연관규칙에는 트랜잭션, 지지도, 신뢰도, 향상도가 있습니다.(이건 좀 통계적인 개념) 몇개의 상품별로 각 값들을 계산하고 이를 Hadoop으로 어떻게 Map과 Reduce가 진행되는 지에 대한 보여주었습니다. 추천시스템의 상품조합은 많으질수록 성능이 급격히 저하되므로 보통 2개의 조합만 사용하며 이 예에서는 맵과 리듀스를 단 2번만 실행하였는데 Hadoop에 대한 개념은 다 들어가 있으면서 한눈에 이해될 정도의 간단한 예제였습니다.
그럼 Hadoop는 언제 써야 하는가 하면 통계에 아주 좋습니다. 또한 데이터에서 필요없는 부분을 제거하는 ETL(Extract, Transform, Load)이나 데이터 마이닝, 로그파일분석, 인공지능에 적용하기가 좋습니다. 하지만 Hadoop은 무식한 배치성 작업이 아주 강하고 인터렉티브하지 않기 때문에 최종적으로는 RDBMS가 필요합니다. Hadoop으로 추출된 최종데이터만 RDBMS로 올리면 됩니다. 이전에는 이것을 디비가 했지만 이제는 개발자가 해야하는 시대가 되었습니다.
처음에 시작할때 초등학생도 이해할 수 있는 수준이라고 말씀하셨는데 사실 Hadoop은 개념이 약간 어려워서 그닥 믿지 않았는데 진짜 여태들은 설명중 최고로 명쾌한 설명이었습니다. 어떻게 하둡을 이렇게 간결하게 설명할 수 있을까 하는 생각이 들 정도였습니다. Hadoop에 대해서 급 관심이 갔으며 막상하면 여러가지 어려움이 있겠지만 오히려 너무 쉽게 설명을 해주셔서 해보면 금방 하겠는데 하는 착각(?)이 들 정도였습니다. ㅎㅎㅎ Hadoop을 어느정도 이해한 것만으로도 아주 큰 수확중의 하나라고 할 수 있겠네요.
글이 길어져서 자바 커뮤니티 공동 세미나 "자바 개발자를 위한 ‘共感(공감)’을 찾아서" #2 로 이어집니다.
Comments