

Flume #1 소개
얼마전에 Flume을 약간 만져보게 될 기회가 있었습니다. 처음 만져보는 거라 이것저것 헤메면서 만져봤었는데 지금은 다시 안만지고 있고 당분간은 사용할 일이 없을 것 같아서 조금이나마 기억이 남아있을 때 정리를 해 놓습니다.
Cloud쪽은 별로 안만져 보았고 이런 류의 어플리케이션도 처음 만져보기는 했지만 솔직히 Flume은 문서관리가 엉망이고 관련자료도 많지 않습니다. 이번에 만져보면서 처음 Flume을 접했기 때문에 프로젝트의 진행사항같은 것은 전혀 모르기는 한데 보통의 오픈 소스들이 문서관리가 괜찮기 마련인데 Flume은 문서도 완전 엉망에다가 홈페이지 관리도 형편없습니다.
제 가 만져볼 때는 0.9.4였던 것 같은데 지금은 1.1.0이 최신 버전으로 나오고 있습니다. 1.1.0기반으로 다시 좀 테스트해보려고 했더니 다른 문서는 아직 0.9.4기준으로 되어 있고 1.0부터인지(추측입니다.) 1.1.0에는 Flume NG라는 이름으로 부르는 듯 합니다. Flume NG는 FLUME-728 이슈 에 따라 Flume을 리팩토링한 프로젝트 이름 인 데 지금은 Flume NG로 배포되고 있습니다. 개발과정을 추적하고 있지 않고 문서가 많지 않아서 정확한 파악을 잘 못하겠는데 새로 리펙토링해서 그런지 0.9.4에서 하던 방법으로는 실행도 제대로 할 수 없어서 이 글은 flume-0.9.4-cdh3u4 버전을 기준으로 합니다.(Flume NG에 대해 좀 아시면 누가 답변 좀.. ㅠㅠ) CDH3가 의미하는 바는 Cloudera’s Distribution Including Apache Hadoop 즉, Cloudera의 하둡 배포판이고 뒤에 붙은 숫자는 버전 3을 얘기합니다. 지금은 CDH 4 까지 나왔습니다. 그래서 flume-0.9.4-cdh3u4 의미는 CDH 3의 업데이트 4에 포함된(호환되는?? 제가 하둡을 잘 몰라서...) flume-0.9.4를 이야기 합니다.
문서화가 엉망이라고 했었는데 한두달 전에 제가 볼 때는 그래도 0.9.4에 대한 유저가이드나 이런저런 문서가 링크되어 있었는데 Flume NG로 바꾸어서 인지 (다른 문서도 없이) 프로젝트 사이트에서 문서 링크를 제거해 버려서 뭐 찾아 볼 수가 없습니다. 0.9.4와 관련된 문서는 클라우데라쪽 아카이빙 페이지에 있습니다. 문서에 있는 이미지들이 깨지는 것으로 보아 이 링크도 언제까지 유지될지는 잘 모르겠습니다. 그나마 유저가이드가 설명이 잘 되어 있고 Flume의 유저 가이드를 한글화 해 놓으신 분이 계신데 초벌 번역이라서 그런지 번역질은 그리 높지 않다고 들었습니다.(저는 한글문서의 존재를 모르고 영문으로 읽어서 한글문서는 보지 않았습니다.) 글을 쓰려고 문서를 찾는 중 아카이브 사이트에서 flume 1.1에 대한 문서들 을 찾을 수 있었지만 내용이 너무 빈약하고 새로 보고 테스트하기도 좀 어려워서 그대로 0.9.4를 기준으로 정리합니다.
Flume이란?
 Flume 홈페이지 에 가면 Flume을 다은과 같이 정의하고 있습니다. 구글에서 Flume을 검색하면 github의 저장소가 나오는데 저장소에서 안내하고 있듯이 지금은 아파치 인큐베이터로 이동해서 아파치쪽에서 관리가 되고 있고 Github의 저장소 페이지는 더이상 운영하지 않습니다.
Flume 홈페이지 에 가면 Flume을 다은과 같이 정의하고 있습니다. 구글에서 Flume을 검색하면 github의 저장소가 나오는데 저장소에서 안내하고 있듯이 지금은 아파치 인큐베이터로 이동해서 아파치쪽에서 관리가 되고 있고 Github의 저장소 페이지는 더이상 운영하지 않습니다.
Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. Its main goal is to deliver data from applications to Apache Hadoop's HDFS. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. The system is centrally managed and allows for intelligent dynamic management. It uses a simple extensible data model that allows for online analytic applications.
정의가 무척 길게 나와 있고 대부분의 오픈소스가 그렇듯이 다양한 미사여구가 들어가 있습니다. 쉽게 말하면 Flume은 Log aggregator 즉 로그 수집기입니다. 수많은 서버에 분산되어 있는 많은 양의 로그 데이터를 flume을 통해서 한 곳(기본적으로는 HDFS)으로 모을 수 있도록 해줍니다. 비슷한 류의 어플리케이션으로는 페이스북이 만든 Scribe 가 있습니다.(이 둘보다 괜찮다고 한 것도 들었었는데 이름이 기억안나네요.) Flume은 클라우드 쪽에서 잘 나가는 회사인 cloudera 에서 만들었고 앞에서 얘기했듯이 지금은 아파치 인큐베이팅으로 옮겨갔습니다.(주 개발은 cloudera에서 하는듯 합니다.)
Flume의 아키텍처
다음 그림처럼 Flume은 3 계층으로 구성되어 있습니다. 에이전트 계층, 컬렉터 계층, 스토리지 계층 3가지입니다.
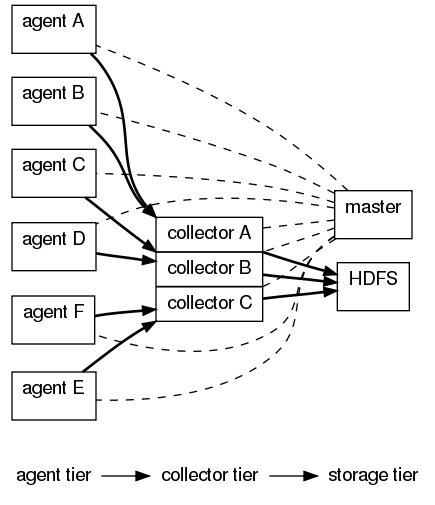
에이전트 계층에서 각 에이전트 노드는 수집할 로그데이터가 생성되는 머신에 설치하는 것이 일반적입니다. 머신이 여러개 일 경우 각 머신마다 에이전트 노드를 설치하고 이 에이전트 노드가 에이전트 계층을 형성합니다. 에이전트노드에서 수집한 데이터는 컬렉터노드로 전송이 됩니다. 컬렉터노드는 보통 다른 머신에 있으며 당연히 여러 컬렉터노드로 구성할 수 있습니다. 에이전트 노드에서 컬렉터노드로 데이터를 전송할 때는 어떤 데이터를 어디로 보내고 어떻게 처리할 것인지 등에 대한 데이터흐름(data flow)를 설정할 수 있고 이 설정대로 데이터를 이동시켜 스토리지 계층에 저장합니다.
이 데이터흐름의 설정을 담당하는 것이 마스터노드입니다.마스터는 각 논리적 노드를 런타임에서 설정할 수 있습니다.(이 부분이 플럼의 가장 큰 장점이라고 생각합니다.) 각 노드를 실행해 놓은 상태에서 마스터 노드를 통해서 자유롭게 설정을 변경할 수 있습니다. 즉 이는 어디서 로그데이터를 가져오고 어떻게 처리하고 어디에 저장할 것인지를 동적으로 계속 변경할 수 있습니다.
노드는 물리적 노드와 논리적 노드로 구분할 수 있습니다. 물리적 노드는 머신의 한 JVM위에서 동작하는 하나의 자바 프로세스입니다. 물리적 노드도 논리적 노드와 동일하게 동작하지만 물리적 노드위에는 다수의 논리적 노드를 생성할 수 있습니다. 그래서 필요한 용도에 따라 여러가지 논리적 노드를 생성해서 데이터 흐름을 구성할 수 있습니다. 각 논리적 노드(에이전트와 컬렉터 모두 포함)은 상당히 유연한 추상화입니다. 모든 논리적 노드는 2가지 컴포넌트를 가지고 있는데 이벤트를 생산하는 source와 이벤트를 소비하는 sink입니다. source는 어디서 데이터를 수집하는 지를 지정하고 sink는 어디로 데이터를 보내야 하는지를 지정합니다.(추가적으로 source와 sink에는 decorator를 설정해서 데이터를 전달하는 중에 어떤 처리를 할 수 있습니다.) 컬렉터와 에이전트는 사실 동일한 노드 소프트웨어에서 동작합니다. 즉, 동일한 노드이지만 설정이 다를 뿐입니다.
Flume의 신뢰도와 확장성
Flume은 신뢰할 수 있는 데이터 전송을 위해서 3가지 수준의 신뢰도를 지원합니다.
-
end-to-end 신뢰도는 flume이 이벤트를 받으면 최종지점까지 보장한다는 의미입니다.
-
store on failure 신뢰도는 데이터를 보내다가 실패했을 때 로컬디스크에 저장했을 때 다시 보낼수 있게 되거나 다른 컬렉터를 선택할 때까지 기다린 후에 다시 보냅니다.
-
best-effort 신뢰도는 처리중인 데이터가 실패했을 때 잃어버릴 수도 있다는 의미입니다. 이는 가장 약한 신뢰도이지만 가장 경량입니다.
Flume은 수평적 확장을 지원합니다. 이는 시스템에 추가적인 머신을 추가함으로써 전체 쓰루풋을 향상시킬수 있다는 의미입니다. 각 계층별로 부하량에 따라 노드를 추가해서 전체적인 성능을 향상시킬 수 있습니다.
이 글은 Flume #2-1 간단한 사용예제 로 이어집니다.
아시는 내용일지 모르겠지만 클라우데라에서 0.94버젼까지 만들고 아파치로 이전되서 환골탈퇴되서 Flume-NG라고 부릅니다 기존에 클라우데라는 Flume-OG라고 부르기도하구요 구조도 다르죠 ㅎ NG는 아직 윈도우는 미지원입니다 ㅠㅠ 혼자 이클립스에서 삽질중이긴한데.. ㅎ 쉽지않네요 ㅎㅋ
아~ 그런 사연이었군요.. NG는 그럼 new generation인가요?(어원을 찾을수가 없더라구요.) 글에도 썼듯이 히스토리에 대해서는 아는 바가 없어서요... 좋은 정보 감사합니다. ㅎ github에서 이동한지는 1년가까이 된것 같은데 한 두달전만 해도 인큐베이팅 사이트에도 0.9.4가 걸려있더니 지금은 flume-ng로 바뀌었네요... 맘같아서는 flume-ng로 글을 쓰고 싶었는데 달라진것도 많고 가이드가 부실해서 해볼수가 없더라구요... 계속 flume을 쓰는건 아니라 다시 첨부터 파보기는 어려워서 그냥 0.9.4를 기준으로 올렸네요.
참고로, FLUME-NG는 New Generation이 아니고 next generation of Flume 이예욤 :-) 작년 이맘때까지 0.9.x ~ 0.9.4-SNAPSHOT 까지만 쓰다가 팀 바뀌면서 관심을 못 가진 듯 ㅋ 그 때 기억은 너무 자주 패치되는게 많아서 코드 수정 및 패치 해주기 힘들었던 기억이.. ㅎㅎ
next generation이군요.. 검색해도 어원이 잘 안나오더라구요 ㅎㅎㅎ 아직까진 대부분은 0.9.4를 쓰는듯 하네요.... 저는 패치는 적용안하고 그냥 cdh에 포함된거만(지금은 포함안되는듯 하더군요.) 갖다 써서요. ㅎ