

업무로 배포 쪽은 담당하고 있어서 Kubernetes 운영에 많은 참여는 안 하고 있는데 서비스 모니터링을 할 때 CPU usage와 throttling의 관계에 평소 의문을 가지고 있었다. Kubernetes에서 배포할 때 컨테이너의 리소스 request와 limit을 같은 값으로 맞추어서 사용하고 있었는데 CPU 기준으로 보았을 때 request 대비 usage가 꽤 낮음에도 불구하고 스로틀링이 생기는 부분이 신경써였다.
신경은 쓰였지만, 확인은 안 하고 있다가 올해는 이 부분을 봐야 할 필요가 있어서 팀원들하고 추측과 가설을 논의하면서 테스트해보기 시작했다. 그러던 중 Kubernetes resources under the hood를 설 연휴에 읽어보고(총 3편의 글이다) Kubernetes가 CPU 자원을 어떻게 제어하는지 어느 정도 이해하게 되었다.
Kubernetes의 리소스
Kubernetes에서 리소스는 spec.containers[].resources.requests와 spec.containers[].resources.limits로 설정한다.
spec:
containers:
- resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
이 값을 가지고 Pod을 스케쥴링(노드에 배치)하고 리소스를 제어하게 된다. Node의 할당할 수 있는 영역을 보면 Kubernetes가 써야 하는 리소스와 시스템 리소스, eviction을 위한 영역을 제외한 부분을 Pod이 사용할 수 있는 영역으로 설정한 것을 볼 수 있다.
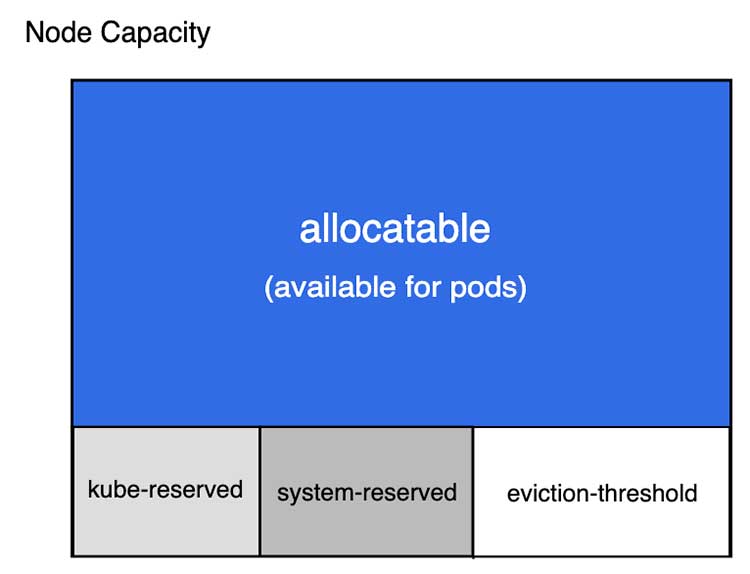
노드에서 팟이 아무리 리소스를 많이 차지하더라도 Kubernetes가 사용하는 영역은 확보하고 있다는 의미이다. 그래서 이론상은 Pod이 리소스를 모두 사용해서 기아 상태(starvation)가 되더라도 Kubernetes가 노드를 제어할 수 있다는 의미가 된다. 이건 꽤 중요한데 컨테이너 이전에 그냥 EC2 인스턴스 등으로 서버를 띄웠을 때 장애 상황에 CPU가 100%가 되어서 SSH 접속도 안 되는 문제 같은 게 생기지 않는다는 의미가 된다. 결국 Kubernetes가 제어할 수 있는 상태라면 일부 팟을 내리거나 하는 등의 조치를 취할 수 있으므로 대응할 수 있게 된다. 이건 Kubernetes 입장에서는 당연히 보장할 수 있어야 하는 부분인데 인터넷에서 찾아보면 그런데도 노드가 제어할 수 없는 상태로 넘어갔다는 얘기를 종종 볼 수 있어서 현실에서 100% 보장할 수 있는지 아직 확신까지는 없다.
compressible 리소스와 incompressible 리소스
일단 이 부분을 감안하고 좀 더 살펴보면 Kubernetes에서 리소스는 compressible 리소스와 incompressible 리소스로 나누어진다.
compressible 리소스는 말 그대로 압축할 수 있는 리소스이다. 컨테이너가 리소스를 필요로 할 때 사용할 수 있는 리소스가 없으면 기다릴 수 있다. CPU가 compressible 리소스이고 Kubernetes는 compressible 리소스에 대해서는 스로틀링으로 대응한다. 사용할 리소스가 없을 때 사용량을 제어하고 CPU가 부족하더라도 팟이 죽거나 하진 않는다.
incompressible 리소스는 압축할 수 없는 리소스로 리소스가 필요할 때 공급받지 못하면 문제가 생기게 된다. 메모리는 incompressible 리소스이고 보통 알다시피 필요한 메모리를 확보하지 못하면 Out Of Memory가 발생하면서 애플리케이션이 죽게 된다.
지금은 컨테이너 리소스 제어에 cgroup을 사용하는데 cgroup v2부터는 메모리도 스로틀링이 된다고 하는데 아직 잘 이해하진 못했다. cgroup v2는 Kubernetes 1.25에서 GA가 되었다.
CPU requests
이 글에서는 리소스 중 CPU만 살펴볼 예정인데 먼저 request가 어떻게 동작하는지를 살펴보자.
spec.containers[].resources.requests.cpu로 설정하는데 CPU는 CPU 단위로 지정하게 되는데 1 CPU라고 한다면 1 물리 CPU 코어나 1 가상 코어가 된다. 클라우드에서는 보통 1 가상 코어가 될 것이고 1, 0.5로 지정할 수도 있지만 1000m, 500m으로 지정할 수도 있고 m 단위 표기를 권장한다. 1000m은 1 CPU를 의미한다. 이 requests는 기본적으로 Pod을 스케줄링하는 데 사용하는데 1000m으로 설정했다면 노드 중 1 CPU의 여유가 있는 노드에 배치된다.
이 CPU requests의 값은 스케쥴링된 후에는 CPU share라는 단위로 변환된다. 500m을 설정했다면 1024를 곱해서 1024 x 0.5로 512 CPU share가 된다. 왜 CPU share라는 값으로 변환하는지 의아할 수 있는데 이는 노드 내에서 CPU를 얼마나 사용할지 계산하기 위해서이다. 노드 내에서 CPU 스케줄링은 CFS(Completely Fair Scheduler)가 담당하게 되는데 CPU가 부족할 때 CFS가 이 CPU share의 값을 이용해서 더 많은 share를 가진 프로세스에 CPU time을 할당하게 된다. 참고로 Kubernetes에서 requests를 아예 설정하지 않으면 2 CPU share가 설정된다.
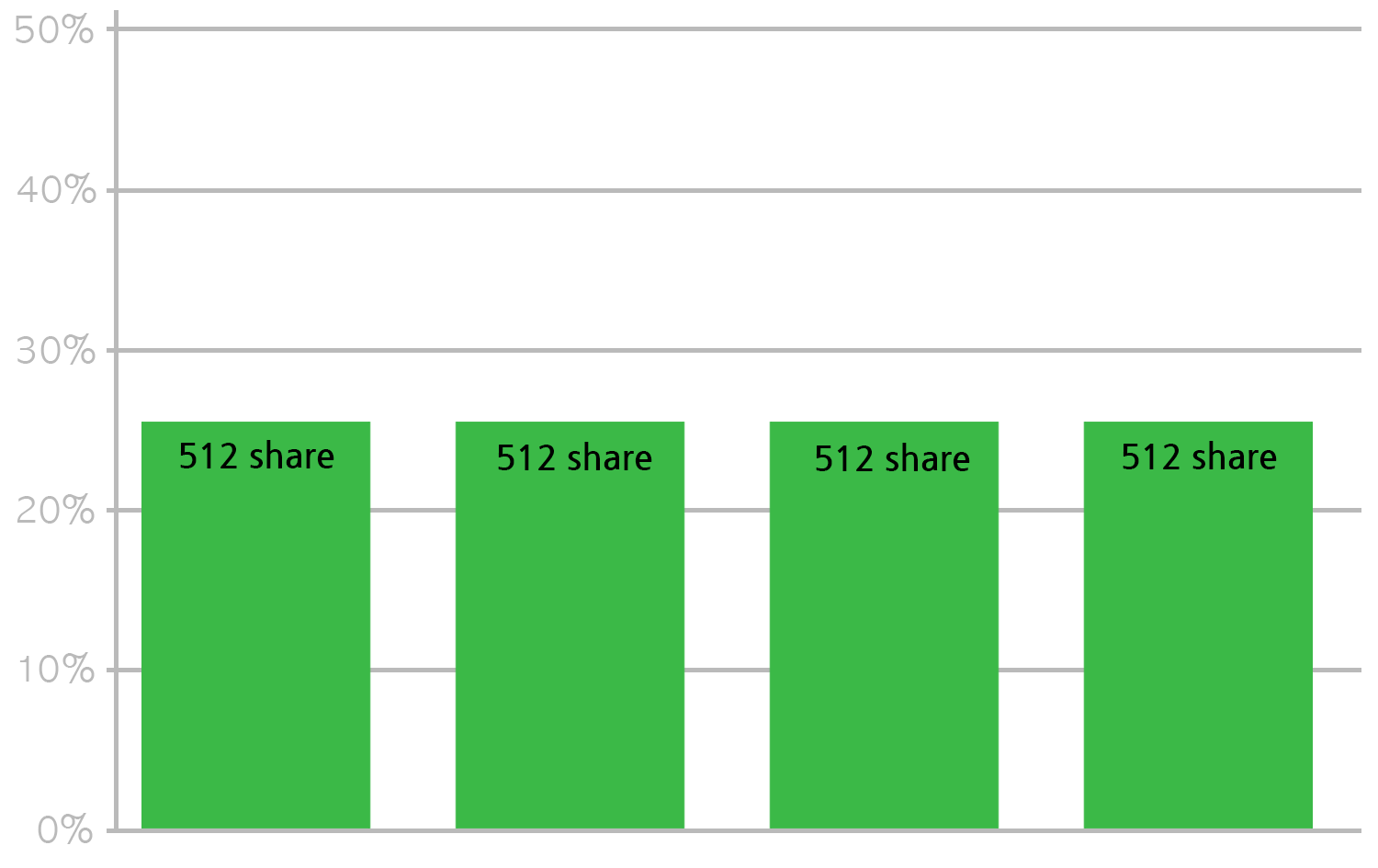
위처럼 노드에 512 CPU share(500m cpu request)를 가진 4개의 컨테이너가 있고 이 컨테이너가 CPU를 최대한으로 쓴다고 하면 위처럼 CPU time을 25%씩 나누어 쓰게 된다. 정확히는 컨테이너 기준보다는 cgroup 단위가 되는데 컨테이너라고 생각해도 크게 문제는 안 될 것 같다. CPU time으로 CPU 사용량을 얘기하는 것은 뒤에서 더 설명할 것이다. 이를 CPU share라고 부르는 이유가 여기서 나오는데 총 CPU share에서 자신이 가진 CPU share 만큼은 사용할 수 있게 되는 것이다.
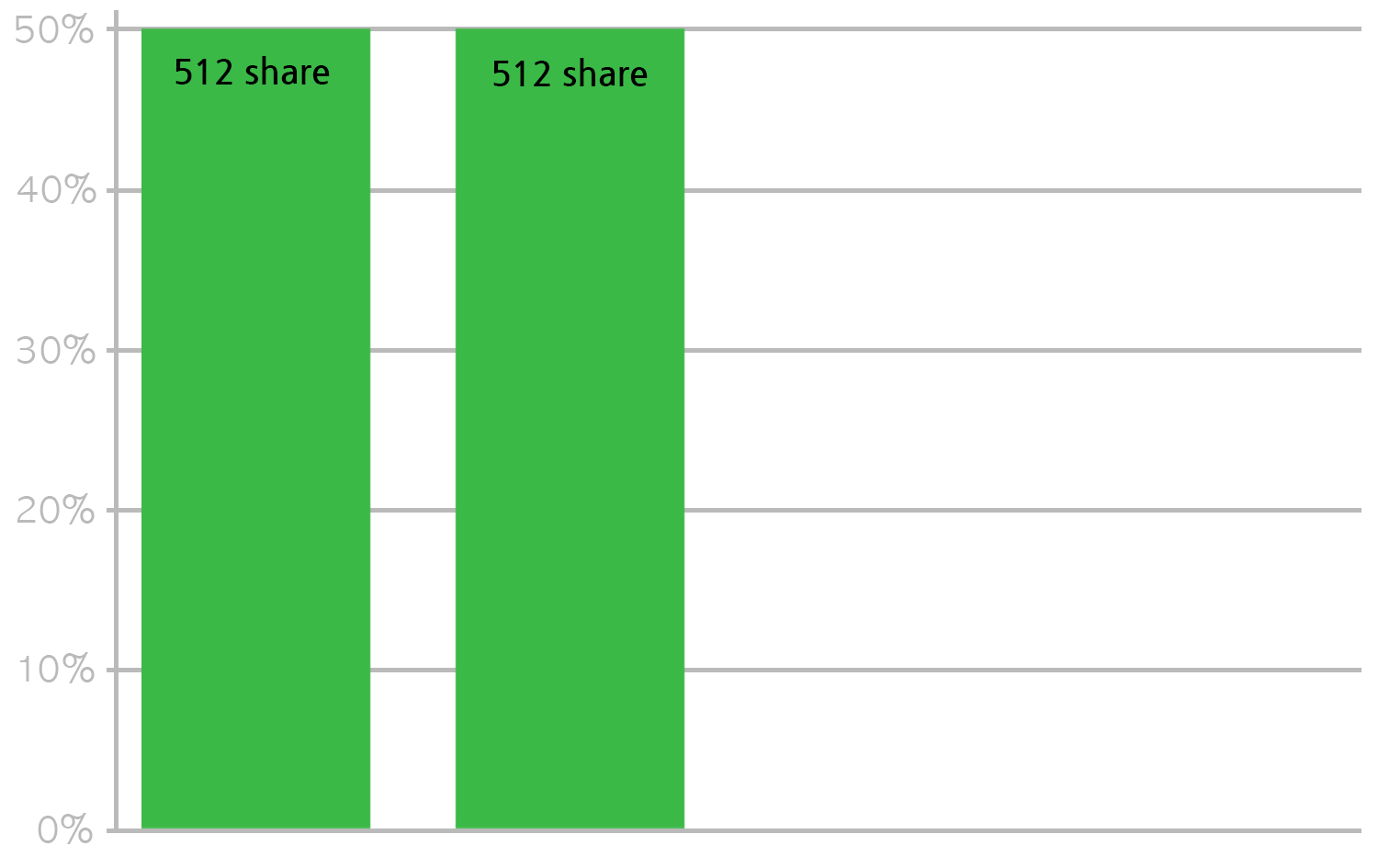
비율로 CPU를 사용한다는 것을 이해하는 것이 중요하다. 같은 상황에서 512 CPU share를 가진 2개의 컨테이너만 스케쥴링되어 있다면 아까와는 달리 50%의 CPU time을 사용할 수 있다. 해당 노드에 스케쥴링된 총 CPU share에서 자신이 가진 CPU share의 비율만큼이 사용할 수 있는 최대 CPU time이라고 생각해도 된다.
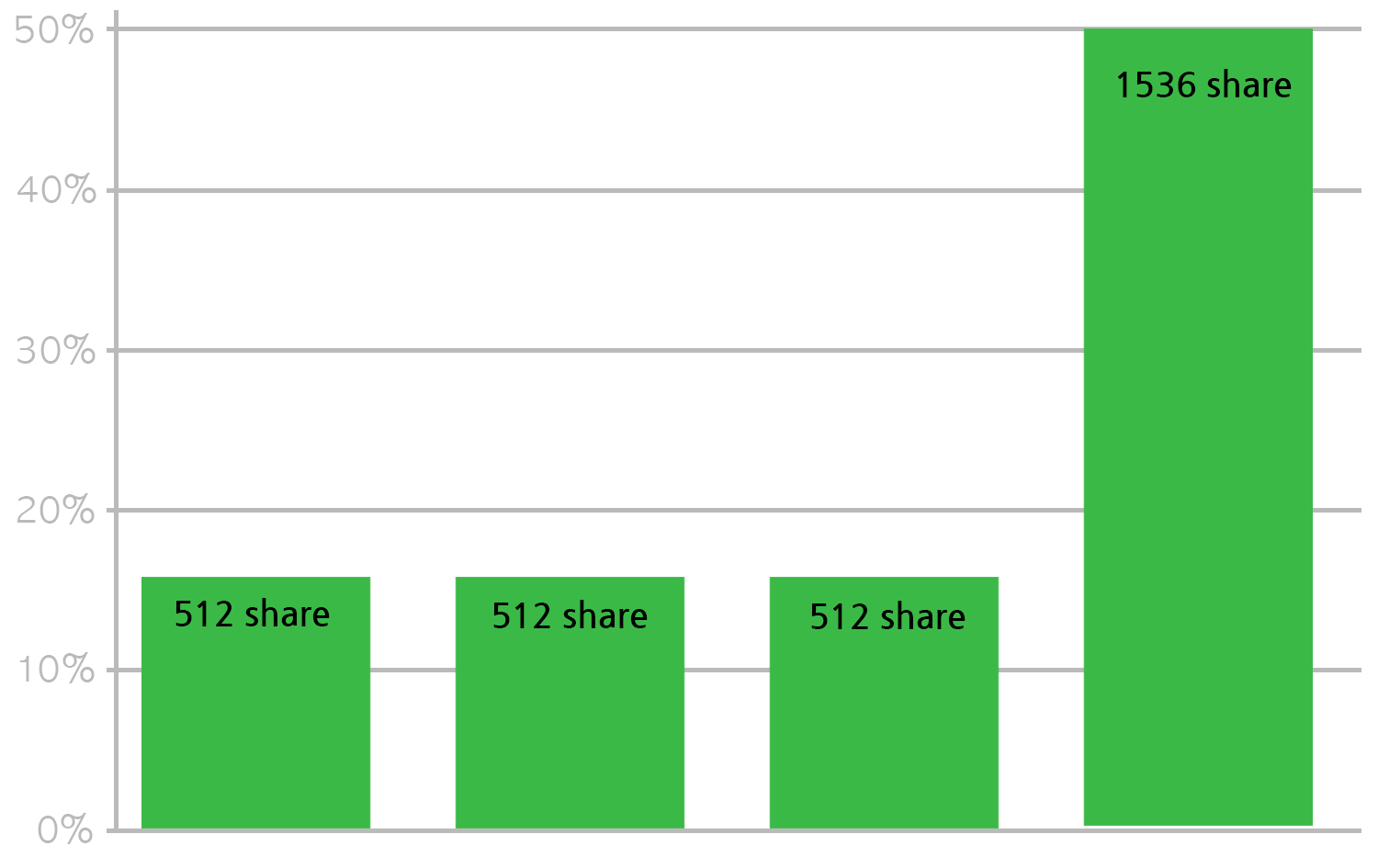
아까와 달리 4개의 컨테이너가 있는데 1개의 컨테이너는 1536 CPU share를 가진다고 하면 이 컨테이너가 50%를 사용하고 다른 컨테이너가 16.7%씩 사용하게 된다. 이는 각 컨테이너가 CPU를 모두 최대한 쓰려고 할 때 어느 정도까지 사용할 수 있는지에 대한 비율이다.
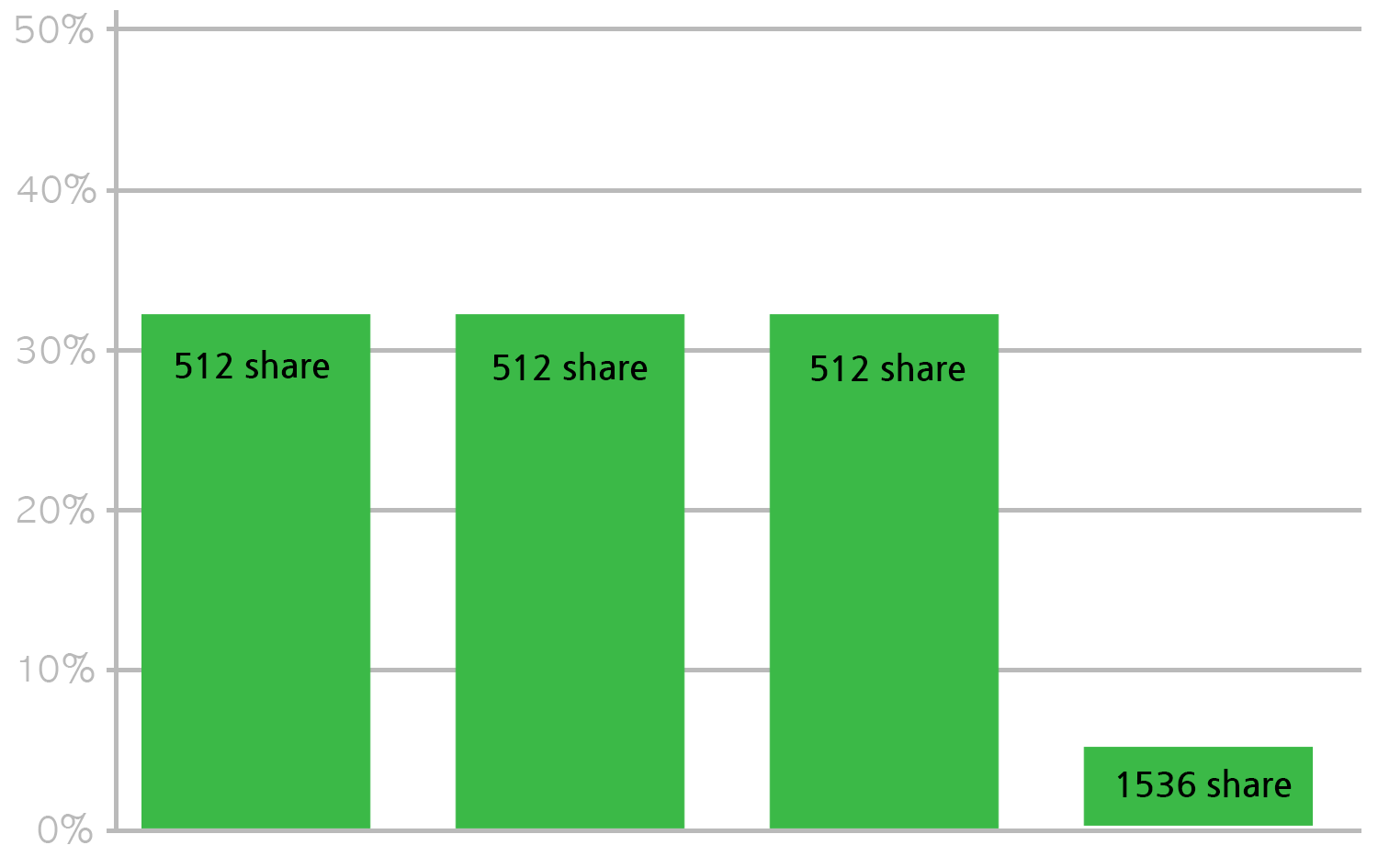
다음처럼 1536 CPU share를 가진 컨테이너가 50%까지 쓸 수 있지만 실제로는 5%만 사용하고 있고 다른 3개의 컨테이너는 CPU를 최대한 쓰고 있다고 한다면 5%를 뺀 95%의 CPU time을 나머지 3개의 컨테이너가 나누어 쓰게 된다.
여기서 CPU share의 사용량을 설명하면서 노드의 CPU가 몇 개인지를 얘기하지 않은 것을 알 수 있는데 이는 노드의 CPU 개수와 상관없기 때문이다. 위에서 말한 CPU share 비율에 따라 나누어 쓰는 것은 32코어이든 2코어이든 똑같다. 즉, 내가 가진 CPU share의 절댓값보다는 컨테이너에 들어온 전체 CPU share에서 얼마를 차지하고 있는지가 중요하다는 것이다. 하지만 같은 수치를 가지고 스케줄링을 하므로 실제적으로는 최소한으로 보장되는 CPU time이 된다. request.cpu를 1000m으로 지정했고 10코어를 가진 노드에 스케쥴링되었다면 해당 컨테이너만 있다면 10코어를 필요할 때 혼자 다 쓸 수 있게 되겠지만 다른 컨테이너가 최대한 들어와도 9000m(9216 CPU share)이 더 들어올 수 있으므로 해당 컨테이너는 최소한 1코어는 쓸 수 있게 된다.
그래서 request.cpu는 스케줄링뿐만 아니라 컨테이너 생명주기 전체에서 보장받아야 하는 CPU를 설정하게 된다.
CPU limits
이제 CPU limits을 살펴보자. CPU limits는 spec.containers[].resources.limits.cpu로 설정할 수 있고 그 이름대로 컨테이너가 사용할 수 있는 CPU 리소스의 제한을 설정한다. 그러면 그 제한이 어떻게 동작하는지 알아야 하는데 CPU를 스케줄링하는 CFS에는 cpu.cfs_peroid_us와 cpu.cfs_quota_us 두 가지 파라미터가 있다.
cpu.cfs_peroid_us는 CPU period의 기본값으로 Kubernetes에서는 100ms가 된다. kubelet에서 수정할 수 있다지만 그냥 100ms 고정값이라고 생각해도 무방하다. cpu.cfs_quota_us는 이 100ms의 cpu.cfs_peroid_us에서 컨테이너가 어느 정도의 시간을 쓸 수 있는지에 대한 쿼터를 의미한다. 보통 PC를 사용할 때 CPU의 사용을 퍼센티지로 생각하기 때문에 CPU의 일부를 사용한다고 생각하고 있어서 이를 CPU time으로 전환해서 생각하는 게 어려웠다. 하지만 CFS에서는 100ms CPU time을 기준으로 이중 얼마나 사용할 수 있는지가 중요해진다.
1 CPU를 사용한다는 의미는 100ms에서 100ms의 CPU를 사용할 수 있게 된다는 의미가 된다. 설명이 좀 어려운데 예를 들어본다면 공용 오피스에서 회의실을 사용하는데 cpu.cfs_peroid_us가 1시간이라고 한다면 1시간 이내에 몇분을 사용할 수 있냐가 cpu.cfs_quota_us가 된다. 이는 회의실의 몇 퍼센트를 쓰냐의 문제가 아니라 1시간 내에서 몇분을 사용하냐가 되고 1시간이 지나면 쿼터는 다시 리셋되게 된다. 1시간의 회의실 사용 시간 중 30분을 사용한다면 30분을 한 번에 사용할 수도 있고 3분씩 10번에 나누어서 사용할 수 있고 다 사용하면 더는 회의실을 사용하지 못할 것이고 다 사용하지 못하더라도 1시간이 지나면 다시 30분을 사용할 수 있게 된다.
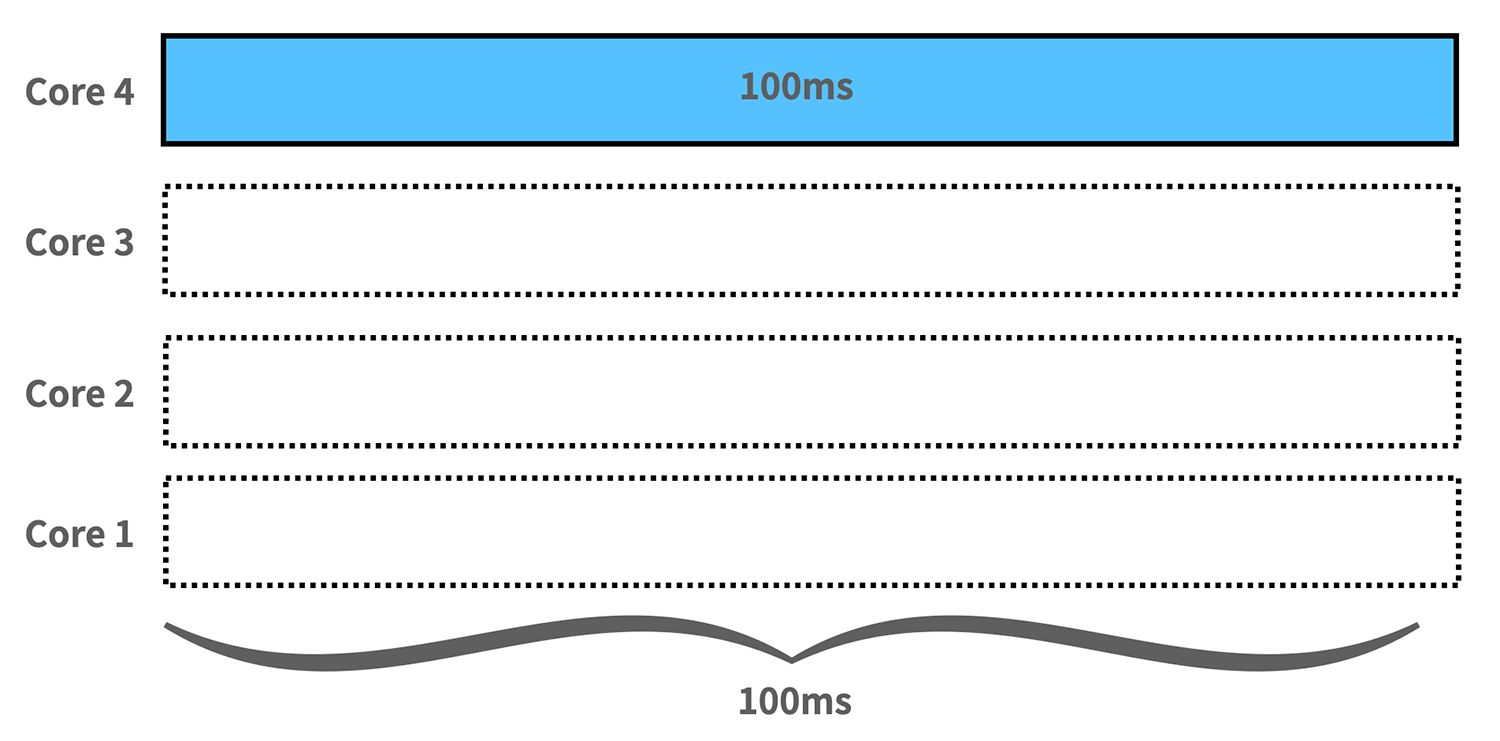
limits.cpu을 1000m으로 설정하면 1 CPU를 사용한다는 의미가 되므로 1 CPU의 단위인 100ms를 전부 사용할 수 있는 100ms가 Quota가 된다. 그래서 Node.js처럼 싱글 스레드를 사용하는 애플리케이션이라면 위처럼 100ms를 다 쓸 수 있게 된다.
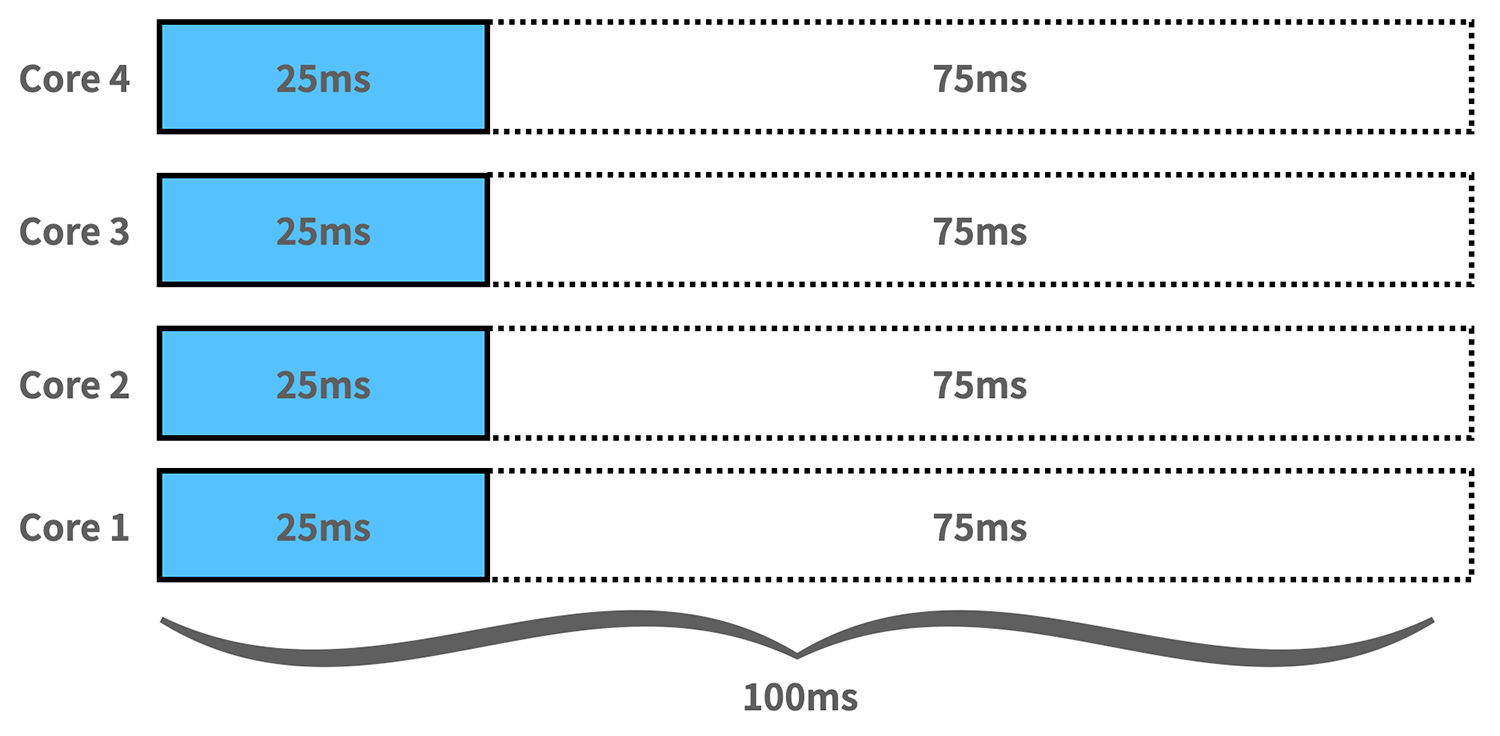
하지만 애플리케이션이 멀티스레드나 멀티프로세서라면 얘기가 달라진다. 위처럼 4개의 스레드를 사용해서 4개의 코어가 동시에 사용된다고 한다면 똑같이 1000m CPU limits가 할당되어 100ms 쿼터를 받는다고 하더라도 4개 코어가 동시에 일하면서 CPU time 100ms를 25ms 만에 소진할 수 있게 된다. 이렇게 되면 할당받은 쿼터를 다 소진했으므로 더는 CPU time을 할당받지 못하고 남은 시간 75ms 동안은 스로틀링이 걸려서 일을 하지 못하고 대기하게 된다. 물론 다음 100ms period에서는 다시 100ms의 쿼터를 할당받게 된다. 이렇게 되면 75%의 스로틀링이 걸렸으므로 75%의 스로틀링이 걸렸다고 표현한다.
즉, 컨테이너의 애플리케이션이 얼마나 많은 코어를 사용하냐에 따라 필요한 쿼터는 달라질 수 있고 그에 맞는 CPU limits를 지정해 주어야 한다.
결론
Kubernetes resources under the hood는 다음을 제안한다.
- CPU request는 컨테이너가 사용하기를 원하는 CPU의 상대적 비중으로 설정해라.
- 예상되는 CPU usage보다 낮게 설정하지 말아라.
- 애플리케이션의 스레드/프로세스 수보다 많이 사용할 수는 없으므로 그보다 높게 CPU requests를 설정할 필요는 없다.
- 성능을 원한다면 CPU limits를 설정하지 말아라.
위 내용을 이해하고 나서는 나는 CPU limits를 해제하는 쪽을 지지하게 되었다. 물론 시끄러운 이웃 문제를 피하려면 CPU limits를 설정하는 것이 좋겠지만 이는 노드 전체의 CPU에 여유가 있음에도 불구하고 과도하게 CPU에 스로틀링이 걸려서 CPU를 사용할 수 있을 때도 오히려 제대로 사용하지 못하게 만든다고 생각한다. 그리고 CPU 스로틀링때문에 적절한 CPU usage도 파악하기가 어렵게 만든다고 생각한다. 결국 CPU 스케줄링을 CFS가 하게 되는데 CPU requests만으로도 비율을 제대로 설정한다면 서로 크게 영향받지 않으면서도 여유 있을 때는 CPU를 충분히 사용할 수 있게 해준다고 생각한다.
물론 이는 이론적인 부분을 공부한 것이고 실제로 사용할 때 경험해보면 예외 상황을 만나게 될 수도 있다. 결국 문제 상황은 모든 컨테이너가 CPU를 과도하게 사용하려고 하는 경합 상황일 때 발생할 것이지만 그때를 위해서 평소에 스로틀링을 과하게 거는 것보다는 평소에 충분히 사용하고 경합 상황을 대처하기 위한 경험을 쌓는다는 것이 더 낫겠다고 생각하고 있다.
Kubernetes resources under the hood에도 나온 얘기지만 Kubernetes 프로젝트 초기 멤버이면서 지금도 참여하고 있는 Tim Hockin도 같은 말을 하고 있다.

또한 Kubernetes에는 HPA가 있고 HPA는 requests 기반으로 동작하기 때문에 트래픽이 몰린 상황에 스로틀링이 걸리기보다는 여유 있는 CPU 자원을 끌어다가 사용하면서 HPA로 인해서 Pod이 늘어나면 다시 CPU usage는 줄어들 것이기 때문에 성능은 최대한 끌어올리면서 "시끄러운 이웃" 문제도 충분히 완화할 수 있다고 생각한다.
이번에 공부한 내용을 바탕으로 여러 시도를 하고 있는데 기회가 된다면 또 정리해서 올려보려고 한다.

Comments