

Vasili는 정규식에 대해서 잘 모르면 Regular Expressions for Dummies 스크린캐스트 시리즈를 보기 권하고 있습니다. 시간내서 보면 꽤 도움이 될듯 합니다. 자리 잡고 스크린캐스트 보게는 잘 안되는것 같습니다. 글을 읽어도... ㅎㅎ
정규표현식을 공부해도 막상 적용하려면 약간 막막하고 헷갈리기 마련인데 웹개발할 때 보통 많이 사용할 만한 내용을 위주로 설명해 주었기 때문에 이해하기도 쉽고 활용해서 쓰기에 꽤나 유용할 듯 보입니다. (위에도 간단히 밝혔지만 nettuts+의 올라온 포스팅을 번역,정리한 내용입니다.) 간단한 정규표현식 문법은 전에 올린 포스팅을 참고하시면 될 것 같습니다.
Matching a Username

// Pattern
/^[a-z0-9_-]{3,16}$/
문자열의 시작부분을 찾는 ^ 다음에 소문자(a-z)나 숫자(0-9), 언더스코어(_), 하이픈(-)가 나올 수 있고 {3, 16}은 앞의 캐릭터들( [a-z0-9_-] )이 최소 3개에서 15개 이하로 나와야 하고 문자열의 끝을 의미하는 $가 마지막에 나옵니다.
Match되는 스트링 : my-us3r_n4m3
Match되지 않는 문자열 : th1s1s-wayt00_l0ngt0beausername (너무 김)
Matching a Password

// Pattern
/^[a-z0-9_-]{6,18}$/
username부분과 아주 유사합니다만 유일하게 다른 부분은 글자수가 3~16자가 아니라 6~18자라는 부분( {6,18} )입니다.
Match되는 스트링 : myp4ssw0rd
Match되지 않는 문자열 : mypa$$w0rd (달러($)표시가 포함되어 있음)
Matching a Hex value

// Pattern
/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
이번에서 문자열의 시작을 찾는 ^로 시작합니다. 그 다음 number sign(#)은 뒤에 물음표(?)가 있기 때문에 옵션입니다. 물음표(?)는 그 앞에 나온 캐릭터가(여기서는 number sign)이 선택사항(있어도 되고 없어도 되는)임을 의미합니다. 그 다음에 나오는 그룹(괄호 안에 있는)에서 2가지 경우를 가질 수 있습니다. 첫번째는 a와 f사이의 소문자나 숫자가 6번나오는 것입니다. 세로바(|)는 3개의 a와 f사이의 소문자나 숫자가 대신 나올수도 있음을 으미합니다. 마지막으로 문자열의 끝을 의미하는 $가 위치합니다.
6개의 문자열을 앞에 둔 이유는 #ffffff같은 Hex값을 파서가 잡아내도록 하기 위한 것으로 반대로 3개의 문자열 검사를 앞에 두었다면 파서는 뒤의 3개의 f는 빼로 오직 #fff만을 잡아냈을 것입니다.
Match되는 스트링 : #a3c113
Match되지 않는 문자열 : #4d82h4 (h 가 포함되어 있음)
Matching a Slug

// Pattern
/^[a-z0-9-]+$/
mod_rewrite나 pretty URL을 사용해 본적이 있다면 이 정규표현식을 사용하게 될 것입니다. 시작 문자열인 ^가 처음에 나오고 뒤이어 소문자, 숫자, 하이픈(-)이 한개 또는 한개이상(+기호)나오고 마지막으로 문자열의 끝인 $가 나옵니다.
Match되는 스트링 : my-title-here
Match되지 않는 문자열 : my_title_here (언더스코어( _ ) 가 포함되어 있음)
Matching an Email
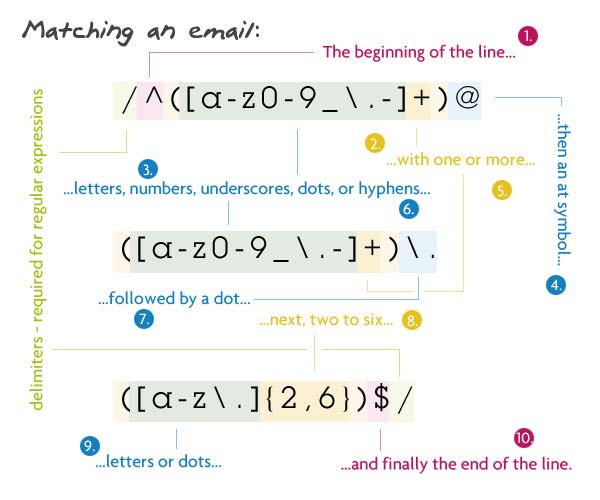
// Pattern
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
문자열의 시작인 ^로 시작하고 첫번째 그룹(괄호 안)에서 1개 또는 그 이상의 소문자, 숫자, 언더스코어( _ ), 점(.), 하이픈(-)가 나옵니다. escape하지 않은 점(.)은 다른 문자를 의미하기 때문에 점(.)은 이스케이프 해줍니다.(\.) 그 뒤에 앳 기호(@)가 나오고 그 다음 1개또는 그 이상의 소문자, 숫자, 언더스코어( _ ), 점(.), 하이픈(-)으로 구성된 도메인명이 옵고 그 후 점(이스케이프된)이 소문자와 점으로 된 2~6개의 문자열이 옵니다. 2~6개로 한 이유는 .co.kr이나 .ny.us같은 국가 TLD(Top-Level-Domain)때문이며 마지막으로 문자열의 끝($)인 옵니다.
Match되는 스트링 : john@doe.com
Match되지 않는 문자열 : john@doe.something (TLS가 너무 김)
Matching a URL
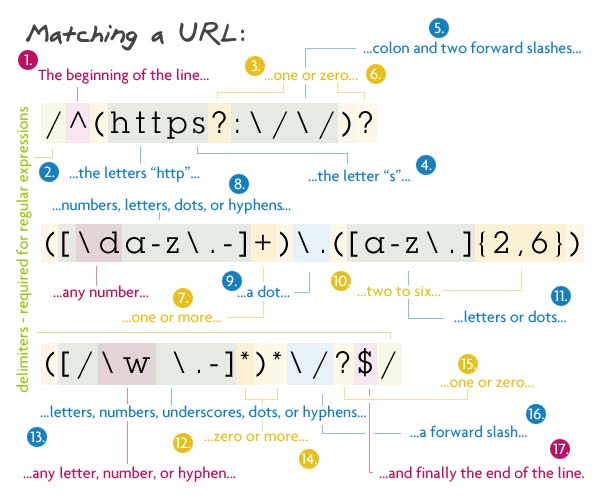
// Pattern
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w_\.-]*)*\/?$/
이 정규표현식은 위에 나온 정규표현식의 최종본이라고 할 수 있습니다.
첫번째 그룹은 모두 옵션인데 이것은 URL이 "http://"나 "https://" 또는 둘다 없이 시작하도록 한다. s뒤에 물음표(?)는 URL이 http와 https를 모두 허용한다. 이 그룹전체를 선택사항으로 하기 위해서 뒤에 물음표(?)를 추가했습니다.
다음은 도메인명으로 한개이상의 숫자, 문자열, 점(.), 하이픈(-)뒤에 또다른 점(.)이 오고 그 뒤에 2~6개의 문자와 점이 옵니다. 이어지는 부분을 추가적인 파일과 디텍토리에 대한 부분으로 이 그룹에서는 갯수에 관계없이 슬래쉬(/), 문자, 숫자, 언더스코어(_), 스페이스, 점(.), 하이픈(-)이 나올 수 있으며 이 그룹은 많은 수의 디렉토리와 파일과 매치됩니다. 물음표(?)대신 별표(*)를 사용한 것은 별표는 0 또는 1이 아닌 0 또는 1개이상을 의미하기 때문입니다. 만약 물음표(?)를 사용했다면 오직 한개의 파일/디렉토리만 매치될 수 있었을 것입니다.
그 뒤에 슬래시(/) 매치되지만 이것은 선택사항이며 마지막으로 문자열의 끝($)이 나타납니다.
Match되는 스트링 : http://net.tutsplus.com/about
Match되지 않는 문자열 : http://google.com/some/file!.html (느낌표가 포함되어 있음)
Matching an IP Address
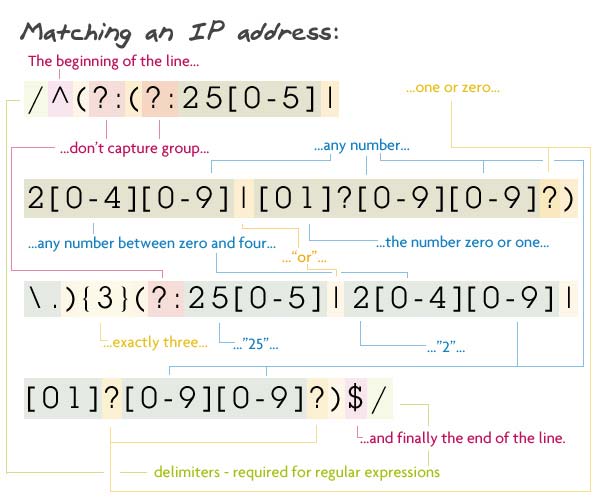
// Pattern
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
자, 저는 거짓말을 하지 않습니다. 이 정규표현식은 제가(Vasili) 작성하지 않았고 이곳에서 가져왔습니다.
정규식이 첫번째로 잡아낸 그룹은 실제로 매치된(captured)된 그룹이 아닙니다. 왜냐하면 ?: 가 그안에 위치하고 있기 때문입니다. ?:는 파서가 이 그룹을 잡아내지 않도록 합니다. 또한 이 잡히지 않는 그룹은 3번 반복되기를 원합니다.(그룹의 끝에 {3}) 이 그룹은 또다른 서브그룹과 점(.)을 담고 있고 파서는 점(.)이 뒤에 있는 서브그룹을 매치하려고 찾습니다.
서브그룹은 또다른 잡히지 않는(non-captured) 그룹입니다. 이것은 0~5가 뒤에 오는 "25"거나 0~4와 모든 숫자가 뒤에 오는 "2"이거나 옵션이 0 또는 2개의 숫자가 이어지는 숫자들의 문자셋의 묶음입니다.
이 3가지가 매치된 이후에 다음 캡쳐되지 않는 그룹으로 들어갑니다. 이것은 0~5가 이어지는 "25" 또는 0~4와 함께 오는 "2" 그리고 마지막에 다른 숫자(0이나 두자리 숫자)가 옵니다.
마지막 문자($)와 함께 이 복잡한 정규표현식이 끝납니다.
Match되는 스트링 : 73.60.124.136
Match되지 않는 문자열 : 256.60.124.136 (첫번째 숫자는 250~255이어야 함)
Matching an HTML Tag
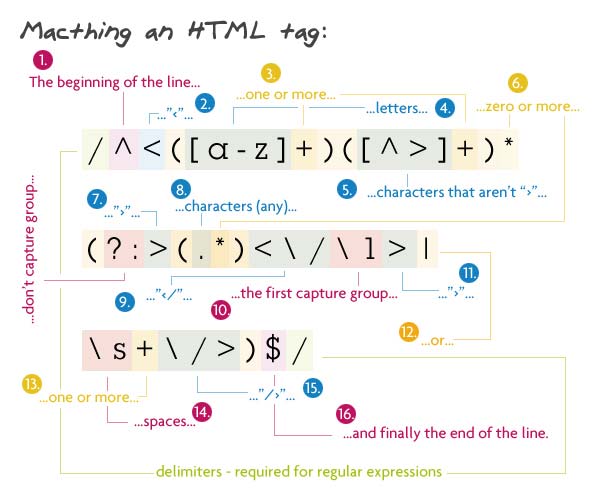
// Pattern
/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/
이 포스팅에서 가장 유용한 정규표현식 중의 하나입니다. 이것은 어떤 HTML태그도 매치할 수 있고 일반적으로 라인의 첫번째에서 시작합니다.
첫번째로 오는 것은 태그이름입니다. 이것은 반드시 한개이상의 문자가 되어야 하며 첫번째로 잡히는 그룹이기도 합니다. 이것은 닫는태그를 잡았을 때 찾아야 할 값입니다. 다음에는 태그의 속성입니다. 이것은 >를 제외한 어떤 문자도 올 수 있습니다. 옵션사항이지만 1개이상의 캐릭터와 매치되기를 원하기 때문에 별표가 사용되었습니다. 플러스기호는 속성과 값을 이루고 별표는 원하는 만큼의 속성(attribute)가 매치될 수 있도록 합니다.
다음으로 세번째 non-capture그룹이 오는데 내부에 >기호가 담길 것이고 컨텐츠부분과 닫는태그가 있습니다.(공백과 슬래시(/), > 기호) 첫옵션은 문자들에 이어지는 >기호를 찾습니다. \1은 캡쳐된 첫번째 그룹에서의 내용을 표현하는데 사용됩니다. 이 경우에는 태그의 이름이 됩니다. 이제 태그이름이 매치되지 않으면 자신의 닫는태그를 찾기를 원합니다. 이것은 "/>"가 이어지는 한개이상의 공백이 필요합니다.
Match되는 스트링 : <a href="http://net.tutsplus.com/">Nettuts+</a>
Match되지 않는 문자열 : <img src="img.jpg" alt="My image>" /> (속성은 >기호를 가질 수 없음)
내용은 아주 좋은데 급하게 작성했더니 번역이 영 그렇네요. 원문가서 보시길....(은근슬쩍 급하게 해서 번역이 이런 척... ㄷㄷㄷ)

좋은내용으로 정규식 공부하고 갑니다
제 블로그로 담아가여~~
예 감사합니다.
좋은 글 감사합니다 ~
정말 유용한 글 이었습니다.
도움되셨다니 다행이네요...
감사합니다.
도움이 많이 되엇습니다.^
댓글 감사합니다. ^^
정규식정보는 많은데..정말 이해하기쉽게 풀이해 주시는분이 없었는데 덕분에 잘 배웠습니다. 그리고 올려주신 정규식도 참 유용한것 같습니다.
성공하세요~
저도 제가 작성한 정규식은 아니고 번역한겁니다.
내용이 유용한걸로 잘 되어 있더라구요.
책임감이 강해보이시는군요.. ^^ 성공하세요~
질문 하나 드립니다.
정수 0~10까지 혹은 정수 한자리수 + 소수 최대 두자리수, 그러니까 0.1~9.99까지만을
받아들이는 정규식을 작성하려고 하는데
HTML, 자바스크립트 양쪽에서 제대로 인식을 못합니다.
이런저런 식으로 바꿔봤는데 다 안되는군요.
/^[0-9]{1}([\.]{1}[0-9]{1,2})$/ 로 하면 그나마 가깝긴 한데 소수점 한자리수까지만 입력되고
/^[0-9]{1}([\.]{1}[0-9]{2})$/로 하면 두자리수까지 인식을 다 하지만 문자열을 인식하지
않고 넘기는 등(a.123 or ...1) 문제가 있습니다.
더구나 /^(\d{1}|10)$|^[0-9]{1}([\.]{1}[0-9]{2})$/ 는 아예 정수 하나 외엔 입력을 못합니다..
어떻게 해야 할까요..
[^0-9][0-9]([^0-9]|[\.])[0-9]{1,2}
이렇게 하면 되지 않을까 싶은데요....
11.99같은 경우 정수의 조건때문에 앞의 1도 걸려들기 때문에 정주 주변에는 정수가 연달아 있을 경우에는 제외하도록 했는데 테스트하시는 데이터가 어떤지 몰라서 원하는 대로 나오실지 잘 모르겠네요. ㅎㅎ
Matching a URL
페턴에 버그있어요 ㅋ
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
underscores 가 빠졌어요 ㅋ
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w_\.-]*)*\/?$/
원문에도 빠져있네요 @.@
그냥 보이길래 ㅎㅎㅎ
오호~ 땡스.. ㅎ 수정해야지 ㅋ
좋은 글 감사합니다..
제 블로그에 담글게요..
네 CCL만 지켜주세요. ㅎ
안녕하세요. 유용한글 잘 보았습니다. 감사합니다. 내용 중 한가지 확인이 필요한 부분이 있어 코멘트를 답니다. 'escape하지 않은 점(.)은 다른 문자를 의미하기 때문에 점(.)은 이스케이프 해줍니다.(\.)' 이부분인데요... 문자집합 '[]' 안에서 점은 escape를 하지 않아도 '다른문자' 가 아닌 문자 '.' 그자체를 의미하는걸로 알고 있어요. 모두를 위해 확인부탁드려요^^;
아~ 그러네요. 항상 이스케이프를 하고 있어서 그부분은 몰랐군요. 좋은 정보 감사합니다.
좋은정보 감사합니다^^
좋은 정보 감사합니다!
도움이 많이 됐습니다 ~ 제 블로그로 담아갈께요 ㅎㅎ 감사합니다
멋집니다.
베껴서 제 블로그에 올립니다.
http://blog.daum.net/andro_java/70
감사합니다.
배끼는걸 당연하듯이 글을 쓰시네요. 이 분은 공들여서 쓰는 시간을 그냥 배껴서 올리는게 당당하듯 글을 다시네요.
입명이 님
전혀 그런 뜻이 아닌데 표현이 잘못 되었다면 미안합니다.
그런 의식이라면 덧글 남기지도 않았겠지요?
올린 페이지까지 명시한 이유도 오해를 받지 않기 위해서입니다.
저는 흔히 아무 데서나 볼 수 있는 내용 몇 줄이 기억나지 않아서 베껴와도 출처를 밝히려고 애쓰고, 또 구글링하다가 어디서 보고 베낀 것인지 메모되어 있지 않으면 출처기억불명 표시라도 남기고, 가입/로긴 등의 문제로 인사 남기지 못한 사연도 붙이고 있습니다.
코딩하다 보면 단 한 줄의 코딩도 얼마나 감사한지 느끼게 됩니다.
부족한 표현으로 불쾌감을 드렸다면 다시 한 번 유감을 표시합니다.
감사합니다.
표현때문에 오해가 있었던것 같습니다. 중간(?)에서 애매하긴 하고 저도 여러가지로 고민중이긴 합니다만 현재 제 글은 CCL by-nc-sa로 배포하고 있어서 출처밝히고 비영리로 퍼가셔도 좋습니다.(sa는 동일 조건으로만 가능하지만 모든 블로그가 이런 CCL을 따르기는 어려운 현실이므로 이부분은 크게 신경쓰고 있진 않습니다. ^^)
흠...도대체 뭐라고 하는건지.....명왕성에서 온 글자인가???
관리자만 볼 수 있는 댓글입니다.