

전에 블로그 글 주제를 요청받기로 하고 올라온 이슈 중에 Ajax를 사용할 때 "뒤로 가기"에 대한 요청이 있었다. 난이도가 아주 높은 건 아니므로 재밌겠다는 생각이 들었다.
일단 최근에는 Ajax를 쓸 때 페이지 뒤로 가기를 직접 구현해 본 적이 없다. 나는 "문서로서의 웹"이라는 기본 개념을 중시하기 때문에 Ajax를 본문 중심으로 헤비하게 쓰지 않는 편이고 SPA(Single Page Application)을 많이 선호하진 않지만, SPA를 하더라도 Angular.js나 React, Backbone 같은 프레임워크에서 제공하는 라우팅을 썼기 때문에 직접 구현해 본 적은 없다. 이 글은 내가 아는 지식 선에서 Ajax를 사용할 때의 "뒤로 가기"에 대해서 정리한 글이지만 그사이에 뭔가 새로운 방법이나 접근이 있을 수도 있는데 그런 경우 알려주면 좋겠다.
글 목록을 보여주는 방식
해당 이슈를 보면 "'페이스북'처럼 목록이 로딩된 상태 (페이징 처리X) 에서 뒤로 가기 처리하는 방법"이라고 나와 있는데 내 지식 범위에서 목록에 대한 관리는 2가지로 나뉜다. 그래서 이해를 도우려면 이 2가지를 먼저 구분하고 설명하는 게 더 좋겠다.
전통적인 방식의 게시판 같은 것을 생각해 보자. 게시판의 글 목록이 화면에 나오고 다음 페이지로 이동하면 글 목록만 Ajax로 불러오게 된다. 이 경우 URL 등으로 정해진 각 페이지 번호에 따라 보여야 하는 글의 목록이 정해져 있다. 물론 새로운 글이 올라오면 목록이 달라지겠지만, 프로그램 관점에서는 불러와야 하는 글의 목록이 정해져 있다.
대신 페이스북이나 트위터 같은 경우의 목록을 생각하면 무한스크롤이다. 페이지별로 나오는 글 목록이 정해져 있는 것이 아니라 URL이 달라지지 않은 상태에서 무한 스크롤을 하게 된다. 그래서 목록의 URL을 복사해서 다른 사람에게 공유한다고 해서 같은 화면을 보지 않는다.(위에서 설명한 상황에서는 같은 주소는 같은 글 목록을 본다.) 이런건 웹사이트의 요구사항에 따라 달라지지만 보통은 URL에 따라서 보여주는 글의 목록을 정하지 않겠다는 의도이다. 그래서 페이스북이든 트위터든 글 목록에서 무한스크롤로 계속 로딩해서 보다가 특정 글을 클릭해서 이동했다가 뒤로 가기로 돌아오면 글 목록을 처음부터 다시 로딩한다.
후자의 경우는 기술적인 문제라기 보다는 서비스의 특성에 관한 것이다. 이어서 설명한 방법을 이용해서 이전에 어디까지 무한스크롤을 했는지 기억했다가 페이지를 로딩하고 사용자를 이 위치에 스크롤 시켜놓는 것은 가능하지만 나는 이 방식은 무한 스크롤과는 좀 맞지 않는다고 생각한다. 이런 상황이 있다면 구현하기 보다는 실제로 무한 스크롤이 정말 필요한가를 고민해 볼 필요가 있다고 생각한다. 그래도 요구하면 할수 없기는 하지만 여기서는 무한스크롤로 보여지는 목록이 아닌 페이징 처리가 된 상태에서 뒤로가기를 구현하는 방식에 대해서 설명하도록 하겠다. 이슈를 올려주신 분이 무한스크롤쪽을 원하는 것 같기도 한데 그렇다면 이슈를 새로 올려주시거나 추가 설명을 해주시면 좋겠다. 그리고 기술적으로 방식은 동일하기 때문에 무한스크롤에서 뒤로가기를 구현하더라도 이글에서 설명하는 방식을 먼저 이해해야 한다.
링크를 이용한 방식
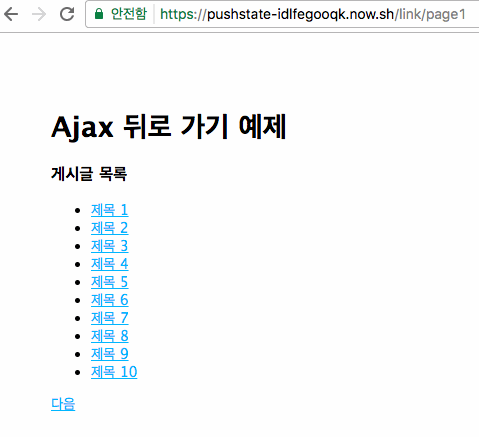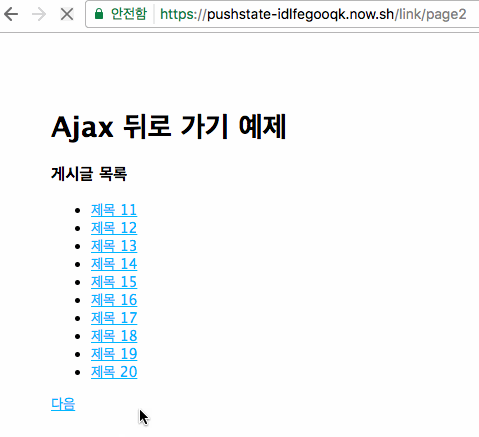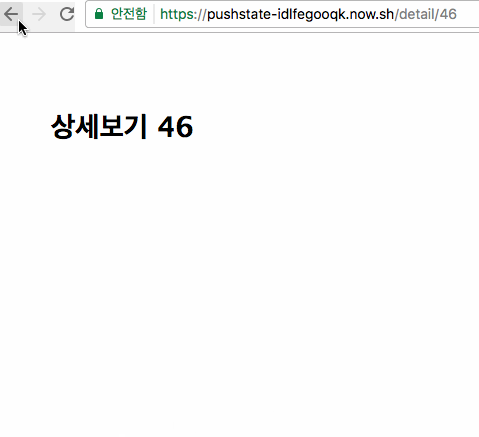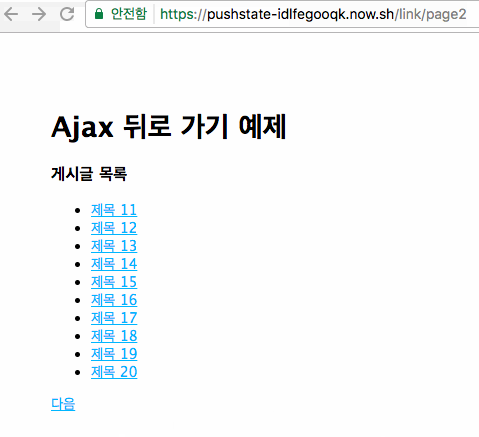
위 방식을 보자. Ajax 등을 쓰지 않고 링크로 목록을 보여주고 페이지관리를 하는 방식이다. 이 방식이 웹의 기본 방식이고 특별한 이유가 없으면 링크로 모든 페이지를 연결하면 된다. 이렇게 하면 모든 페이지에 고유 URL이 있으므로 SEO나 소셜을 대응하는데도 아무런 문제가 없다. "다음"을 클릭하면 다음 10개의 목록을 가져오고 개별 URL을 가지므로 상세 목록에 들어갔다가 뒤로 가기를 해도 이전에 보던 페이지로 잘 돌아간다.
동작하는 예제는 여기에서 볼 수 있다.
여기서는 주소에 /link/page1처럼 되어 있으므로 1페이지에서 1~10의 글 목록을 보여주게 된다. 여기서 어떤 글 목록을 보여줄지는 모두 서버가 관리하고 있으므로 이 목록을 HTML로 만들어서 내려주고 다음 버튼에 대한 링크로 만들어서 내려준다. 브라우저는 다운받은 HTML을 그냥 보여주는 방식이고 "다음" 버튼을 눌러서 /link/page2로 이동하게 되면 서버가 11~20의 글 목록을 HTML로 만들어서 내려주게 된다. 이때는 링크방식이므로 클릭할 때마다 새로운 URL로 이동하게 되고 모든 페이지를 항상 새로 로딩한다. 항상 새로운 URL을 가지므로 "뒤로 가기"를 눌렀을 때도 아무런 문제 없이 동작한다. 이게 전통적인 방식이다.
그래서 /link/page1로 접속하면 다음과 같은 HTML 문서를 내려받게 된다.
<!DOCTYPE html>
<html>
<head>
<title></title>
<link rel="stylesheet" href="/stylesheets/style.css">
</head>
<body>
<h1>Ajax 뒤로 가기 예제</h1>
<h3>게시글 목록</h3>
<ul id="list">
<li><a href="/detail/1">제목 1</a></li>
<li><a href="/detail/2">제목 2</a></li>
<li><a href="/detail/3">제목 3</a></li>
<li><a href="/detail/4">제목 4</a></li>
<li><a href="/detail/5">제목 5</a></li>
<li><a href="/detail/6">제목 6</a></li>
<li><a href="/detail/7">제목 7</a></li>
<li><a href="/detail/8">제목 8</a></li>
<li><a href="/detail/9">제목 9</a></li>
<li><a href="/detail/10">제목 10</a></li>
</ul>
<a href="/link/page2" id="next">다음 </a>
</body>
</html>
Ajax를 이용한 방식
앞의 방식에서는 링크로 연결되어 있으므로 클릭할 때마다 항상 전체 페이지를 새로 로딩하게 된다. 이 데모 페이지는 목록 외에 스타일이나 다른 문서가 없으므로 문제가 될게 거의 없지만 복잡한 페이지의 경우 페이지마다 헤더나 사이드바, 푸터를 로딩하는 건 속도 저하의 영향을 준다. 그래서 등장한 게 Ajax(Asynchronous JavaScript and XML)다. Ajax는 이미 보편화한 기술이지만 약간 설명하지만 제시 제임스 가렛(Jesse James Garrett)이 만든 용어로 Ajax를 이용하면 웹 페이지에서 일부만 로딩해서 갈아치우는 것이 가능해졌고 이후 웹사이트 작성에 큰 영향을 주었다.
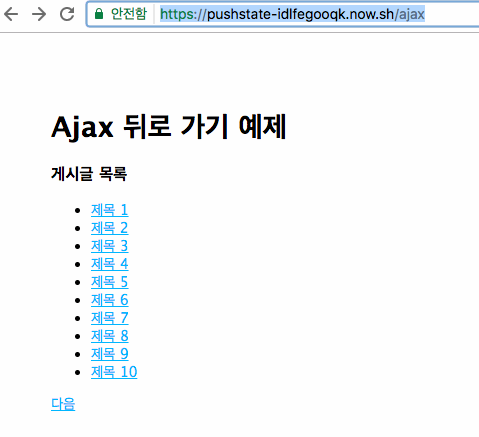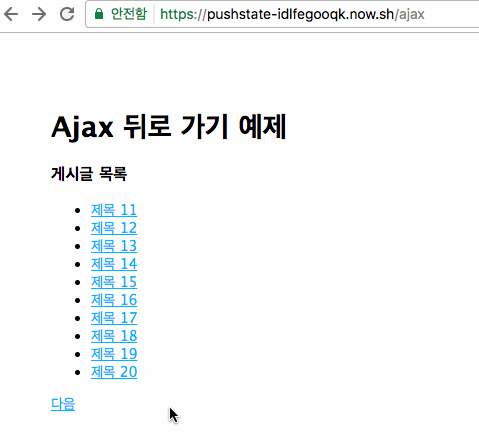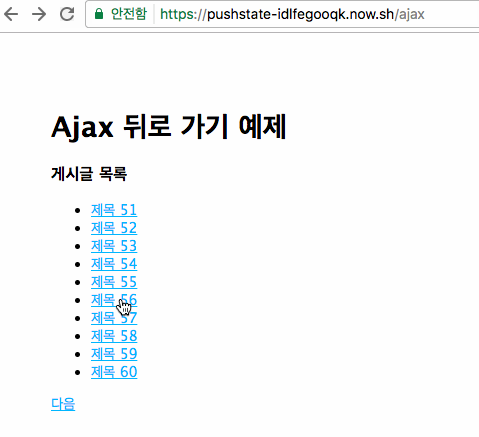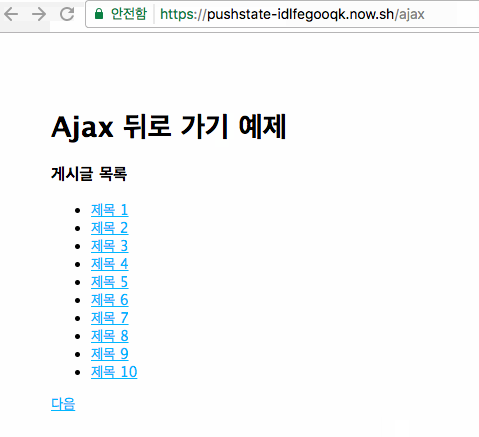
이 예제의 동작을 확인하려면 여기서 볼 수 있다.
이 주소는 /ajax 주소를 가지는데 다음과 같은 HTML을 내려주게 된다.
<!DOCTYPE html>
<html>
<head>
<title></title>
<link rel="stylesheet" href="/stylesheets/style.css">
</head>
<body>
<h1>Ajax 뒤로 가기 예제</h1>
<h3>게시글 목록</h3>
<ul id="list">
</ul>
<a href="/pages/2" id="next">다음 </a>
</body>
</html>
앞의 HTML과 크게 다른 점은 <ul id="list"> 부분에 내용이 안 채워져 있다는 것이다. 이는 빈 내용이 서버에서 내려오고 JavaScript로 데이터를 가져와서 채워 넣게 된다. 이 방식이 Ajax이다. 페이지가 로딩되면 자바스크립트가 실행되는데 여기서 서버에서 글 목록을 가져와서 HTML을 갈아치우게 된다. 게시글을 보여주는 부분이 <ul id="list"></ul>이고 다음 페이지를 보는 버튼이 <a href="/pages/2" id="next">다음</a>이다.
뒤에도 그렇지만 여기의 예제는 데모용으로 최적화된 코드이다. 코드의 품질보다는 동작 방식을 봐주길 바란다. 마지막 두 라인을 보면 위의 다음 버튼 #next에 링크된 주소에서 마지막 페이지 번호를 가져와서 currentPage 변수에 저장한다. 최초에 로딩되었을 때는 다음 페이지는 2페이지이지만 현재 페이지에서 보여줄 페이지는 1페이지이므로 -1을 해서 getList를 호출한다. 여기서 getList는 서버에서 목록을 가져오는 함수인데 서버에 /pages/페이지 번호로 GET 요청을 보내서 받아온 결과를 <li> 목록으로 만들어서 #list 안에 넣어주게 된다. 그리고 #next 페이지도 다음 페이지로 바꿔줘서 클릭 시 다음 목록을 다시 불러오도록 한다. $('#next').click() 부분은 클릭 이벤트를 받아서 버튼의 URL에서 페이지 번호로 다음 목록을 불러오도록 하는 것이다. #next에서 굳이 이렇게 할 필요는 없지만, JavaScript가 없는 경우 최소한의 동작을 보장하기 위해서이다. 물론 이 보장을 하기 위해서는 추가적인 코딩이 더 필요하다. 여기서는 글 목록을 내려주는(여기서는 JSON으로 내려준다.) /pages/페이지 번호의 URL이 하나 더 필요하다. /ajax에서 이 URL로 요청을 보내면 요청받은 글 목록을 JSON으로 내려주게 된다. 자바스크립트는 아래와 같다.
var getList = function(page) {
$.getJSON('/pages/' + page, function(data) {
var list = $.map(data.list, function(l) {
return '<li><a href="/detail/' + l.id + '">' + l.title + '</a></li>'
}).join('');
$('#list').html(list);
$('#next').attr('href', '/pages/' + (+page+1));
});
};
$('#next').click(function(event) {
event.preventDefault();
var page = $(this).attr('href').slice(7);
getList(page);
});
var currentPage = $('#next').attr('href').slice(7);
getList(--currentPage);
이 방식은 앞의 링크방식과 큰 차이점이 있다. 일단 페이지의 URL이 /ajax가 되고 이 페이지 내에서 목록만 계속 달라진다. 그래서 "다음"을 눌러서 몇 페이지로 가든지 글 제목을 클릭해서 상세페이지로 갔다가 "뒤로 가기"를 누르면 다시 1페이지로 돌아온다. 그 이유는 위 스크립트와 링크에서 보듯이 /ajax가 로딩되면 최초 1페이지를 불러오게 되어 있기 때문이다. 그래서 2, 3, 4, 5 페이지를 눌러서 봤다고 하더라도 페이지가 바뀌지 않았으므로 "뒤로 가기"를 누르면 이전 페이지로 가게 된다.
앵커를 이용한 방식
앞에서 설명한 대로 Ajax를 이용하면 전체 페이지를 매번 로딩할 필요 없이 웹페이지의 핵심 콘텐츠 부분만 가져와서 로딩할 수 있다. 그래서 속도가 빠르고 사용자 편의성도 증가하지만 웹 브라우저 입장에서는 페이지의 URL은 바뀌지 않았다. 그래서 "다음" 버튼을 눌러서 새로운 목록을 보더라도 "뒤로 가기"를 누르면 사용자의 기대와 다르게 이전 목록이 나오는 게 아니라 이전 페이지 여기서는 /ajax에 오기 전의 페이지로 이동하게 된다. 이 부분은 사용자의 기대와는 완전히 다른 것이므로 사용자 경험을 몹시 나쁘게 만든다.
그래서 이를 해결하는 방법으로 이용한 것이 앵커다. 예를 들어 babel 프로젝트의 README를 보자. 상단에 목차가 있는데 README 의 주소는 https://github.com/babel/babel/blob/7.0/README.md이지만 각 목차를 누르면 https://github.com/babel/babel/blob/7.0/README.md#faq, https://github.com/babel/babel/blob/7.0/README.md#team같은 식으로 뒤에 #faq, #team 등이 붙는다. 이를 앵커라고 하는데 문서에서 #뒤에 붙은 id를 가진 요소로 자동 이동하게 되는데 이는 서버에 요청을 보내는 것이 아니라 현재 페이지 내에서 이동만 하게 된다. 그리고 이 설명해서 중요한 부분은 브라우저가 이를 URL이 바뀐 것으로 인식하기 때문에 앵커를 이동할 때마다 "뒤로 가기"가 된다. 여러 번 앵커를 이동하더라도 "뒤로 가기"를 누르면 각 부분으로 알아서 이동하게 된다.
동작하는 예제는 여기서 볼 수 있고 이 페이지에 접속하면 다음과 같은 HTML을 내려주게 된다.
<!DOCTYPE html>
<html>
<head>
<title></title>
<link rel="stylesheet" href="/stylesheets/style.css">
</head>
<body>
<h1>Ajax 뒤로 가기 예제</h1>
<h3>게시글 목록</h3>
<ul id="list"></ul>
<a href="/pages/2" id="next">다음 </a>
</body>
</html>
이전에 본 ajax와 거의 비슷하다. 서버가 목록을 내려주는 게 아니라 페이지가 로딩된 후 자바스크립트에서 서버에 목록을 받아와서 화면에 보여준다. 가장 크게 다른 점은 getList에서 목록을 보여준 뒤 window.location.hash = '#page' + page; 부분이다. 그래서 /hash로 접속하면 주소가 /hash#page1로 바뀌게 되고 "다음"을 누르면 /hash#page2로 주소가 달라진다. 새로운 페이지 목록을 불러올 때마다 앵커를 이용해서 주소를 바꾸게 되므로 웹 브라우저는 이를 기록하고 "뒤로 가기"가 가능하게 된다.
여기서 주의할 점은 앵커는 서버에 전달되는 값이 아니라는 것이다. /hash#page1로 접속하더라도 서버에는 /hash만 전달되고 뒤의 #page1는 브라우저가 처리하는 부분이고 뒤로 가기를 할 때도 서버에 새로 요청을 보내지 않는다. 그래서 히스토리는 남지만, 서버가 인식하는 주소는 모두 같기 때문에 각 앵커에 따라 적절한 글 목록을 보여주는 부분을 따로 구현해야 한다. 그 부분이 $(window).on('hashchange', function() {});이다. 주소에서 해시(앵커를 얘기한다)가 달라지는 이벤트를 받아서 해시가 달라시면 해시를 파싱해서 페이지 번호를 가져오고 새로운 목록을 가져오게 된다. 이렇게 하면 매번 글 목록은 요청하게 되지만 사용자로서는 "뒤로 가기"가 기대대로 동작한다. 자바스크립트는 아래와 같다.
var getList = function(page) {
$.getJSON('/pages/' + page, function(data) {
var list = $.map(data.list, function(l) {
return '<li><a href="/detail/' + l.id + '">' + l.title + '</a></li>'
}).join('');
$('#list').html(list);
$('#next').attr('href', '/pages/' + (+page+1));
window.location.hash = '#page' + page;
});
};
$('#next').click(function(event) {
event.preventDefault();
var page = $(this).attr('href').slice(7);
getList(page);
});
$(window).on('hashchange', function() {
var page = parseInt(location.hash.slice(5));
if (!!page && currentPage !== page) {
getList(page);
}
});
var currentPage = $('#next').attr('href').slice(7);
if (location.hash) {
currentPage = parseInt(location.hash.slice(5)) + 1;
}
getList(--currentPage);
동작 원리는 같지만 좀 더 주소처럼 보이려고 만든 것이 해시뱅이다. 해시뱅의 차이점은 /hash#page1를 쓰는 대신 /hash/#!/page1처럼 만들어서 좀 더 URL 주소처럼 만들었다는 것뿐이고 실제 동작은 위에 설명한 앵커방식과 같다. 예전의 트위터도 이 방식이었고 Backbone이나 Angular의 기본 라우팅(HTML5 모드가 아니라면)도 이 방식이었다. 이 방식을 사용하는 이유는 브라우저 지원 폭이 좋기 때문이다. 앵커 자체야 모든 브라우저에서 동작하지만 hashchange 이벤트를 이용하려면 IE 8 이상이어야 한다.
pushState를 이용한 방식
pushState는 ajax가 등장하고 이를 해결하기 위한 편법인 해시뱅이 유행하면서 "뒤로 가기"" 문제를 해결하기 위해 HTML5에 새로 추가된 History API의 새 메서드다. 자바스크립트를 약간 다뤄봤다면 폼 처리를 하면서 history.go(-1);이나 history.forward();같은 기능을 사용해 봤을 텐데 이 History API에 새롭게 추가된 메서드라고 보면 된다. 브라우저는 URL 혹은 앵커가 달라질 때마다 이를 리스트처럼 관리하고 있고 "뒤로 가기"나 "앞으로 가기"를 할 때 이 리스트를 기준으로 이동하게 된다. 그리고 앵커가 달라진 경우가 아니라면 URL이 바뀔 때마다 항상 서버에 요청을 보내게 된다.
하지만 pushState를 사용하면 URL을 바꾸면서 서버에 요청을 보내지 않을 수 있다.
이 예제의 동작을 확인하려면 여기서 볼 수 있다. 이 페이지는 서버에서 다음과 같은 HTML을 내려준다.
<!DOCTYPE html>
<html>
<head>
<title></title>
<link rel="stylesheet" href="/stylesheets/style.css">
</head>
<body>
<h1>Ajax 뒤로 가기 예제</h1>
<h3>게시글 목록</h3>
<ul id="list">
<li><a href="/detail/1">제목 1</a></li>
<li><a href="/detail/2">제목 2</a></li>
<li><a href="/detail/3">제목 3</a></li>
<li><a href="/detail/4">제목 4</a></li>
<li><a href="/detail/5">제목 5</a></li>
<li><a href="/detail/6">제목 6</a></li>
<li><a href="/detail/7">제목 7</a></li>
<li><a href="/detail/8">제목 8</a></li>
<li><a href="/detail/9">제목 9</a></li>
<li><a href="/detail/10">제목 10</a></li>
</ul>
<a href="/pushstate/page2" id="next">다음 </a>
</body>
</html>
HTML을 자세히 보면 처음에 본 링크방식과 유사하게 <ul id="list"> 안에 글 목록이 내려온 것을 볼 수 있다. 이는 서버에서 받아온 HTML 이므로 글 목록은 서버에서 만들어 준 것이다. pushstate는 새롭게 추가된 API이지만 "뒤로 가기" 및 웹에 맞게 구현하려면 해야 할 작업이 좀 더 있다. "다음"을 눌렀을 때는 ajax와 똑같이 동작한다. "다음" 버튼에서 페이지 번호를 파싱해서 getList를 호출하고 서버에서 글 목록을 받아와서 <ul id="list"></ul>안에 새로운 목록을 채워주고 버튼도 다음 페이지를 가리키도록 바꿔준다. 자바스크립트는 아래와 같다.
var getList = function(page) {
$.getJSON('/pushstate/page' + page, function(data) {
var list = $.map(data.list, function(l) {
return '<li><a href="/detail/' + l.id + '">' + l.title + '</a></li>'
}).join('');
$('#list').html(list);
$('#next').attr('href', '/pushstate/page' + (+page+1));
history.pushState({list: list, page: page}, 'Page '+ page, '/pushstate/page' + page);
});
};
$('#next').click(function(event) {
event.preventDefault();
var page = $(this).attr('href').slice(15);
getList(page);
});
$(window).on('popstate', function(event) {
var data = event.originalEvent.state;
$('#list').html(data.list);
$('#next').attr('href', '/pushstate/page' + (+data.page+1));
});
마지막에 앵커를 바꿔주는 대신 history.pushState({list: list, page: page}, 'Page '+ page, '/pushstate/page' + page);가 있는걸 볼 수 있다. 여기서 다음 페이지가 2라면 주소는 '/pushstate/page' + page에서 '/pushstate/page2로 바뀌게 된다. 여기서 주소는 링크방식처럼 바뀌지만, 페이지를 새로 요청하지 않고 Ajax 요청만 발생한다. pushState에 전달되는 인자는 상태 객체(이는 나중에 뒤로 가기를 할 때 사용한다.), 페이지 제목, 페이지 주소가 된다. 브라우저가 관리하는 히스토리 리스트에 새로운 히스토리를 하나 추가하는 것이므로 주소와 페이지, 상태객체를 전달하게 된다.
그리고 $(window).on('popstate', function(event) {}) 부분을 통해 사용자가 "뒤로 가기"를 클릭했을 때 히스토리에서 상태가 나온 것을 탐지할 수 있다. 기본이라면 window.onpopstate로 이벤트를 받아서 event.state를 사용하지만 여기서는 jQuery를 사용했으므로 event.originalEvent.state로 앞에서 pushState에서 넣은 상태객체를 가져왔다. 앞에서 이 상태객체에 목록에 넣은 리스트와 "다음" 버튼에 넣을 페이지 번호를 넣었으므로 그대로 꺼내와서 다시 화면에 보여주도록 했다. 이렇게 하면 앵커를 이용한 방식과는 달리 "뒤로 가기"를 했을 때 서버에 Ajax 요청이 전혀 발생하지 않으면서도 예전 목록을 그대로 화면에 보여줄 수 있다.
추가로 앞의 예제와 크게 다른 점 중 하나가 해당 페이지의 주소가 /pushstate/page1인데 Ajax로 목록을 받아오는 주소도 /pushstate/page2로 완전히 같은 것을 볼 수 있다. 앞의 Ajax나 앵커를 이용한 방식이 화면이 뜬 후에 브라우저에서 목록을 가져온 방식인데 반해 pushState는 URL 자체를 바꿔버리므로 /pushstate/page1에서 "다음"을 눌러서 /pushstate/page2로 이동했다고 하더라도 브라우저의 동작을 생각하면 /pushstate/page2를 복사해서 새 창에 붙여넣으면 똑같은 목록이 나와야 한다.
그러므로 서버는 주소에 따라 해당 목록을 HTML로 내려줄 수 있어야 한다. 이는 서버에서 렌더링하는 방식과 브라우저에서 Ajax로 하는 방식이 섞여 있는 것이므로 서버에서 요청의 Content-Type이 text/html이면 목록을 채운 HTML 페이지를 내려주고 application/json이면 해당 페이지의 목록만 JSON으로 내려주도록 구현한 것이다. pushState를 사용함으로써 할 일은 좀 더 복잡해졌지만 사용자가 느끼는 경험은 훨씬 자연스러워졌다. pushState는 IE 10 이상에서 사용할 수 있다.
Node.js에서 express와 jade를 이용해서 간단하게 작성한 예제이지만 전체 소스를 확인하고 싶다면 저장소를 참고하면 된다.

관리자만 볼 수 있는 댓글입니다.
아 말씀하신 부분을 완전히 이해 못했습니다.
리스트에서 페이지 이동을 한 후에 뒤로가기를 여러번 했다가 다시 앞으로 가기를 하고 다시 뒤로 가기를 하면 맨 첫페이지로 안넘어간다는 얘기신가요? 어떤 예제에서 그런지 말씀해 주시면 확인해 보겠습니다.
관리자만 볼 수 있는 댓글입니다.
네 감사합니다. 바로 시간내서 확인해 보고 예제 다시 정리하겠습니다.
감사합니다 . 잘봤습니다
앵커예제의 오류가나서 예제로써의 역할이..!
어느 브라우저에서 어떻게 오류가 나는지 알려주시면 좋겠습니다.
고맙습니다! 그것은 매우 유용합니다!
감사합니다. 정말 잘 보고 갑니다. 핵심적인 내용이 다 들어가 있네요!
잘 보셨다니 다행이네요. 예시에 좀 오류가 있다는 얘기가 있어서 한번 봐야하는데 시간을 못 내고 있네요.
예제 링크 연결이 안되는데, 혹시 받아볼수 있을까요?
배포했던 서버에 문제가 있었나 보군요. 다시 배포했습니다. 그리고 소스는 본문에 있는 저장소에서 볼 수 있습니다.