


KTH에서 주관하는 개발자 컨퍼런스는 처음이지 싶은데 일반적으로 그냥 이름을 보면 느낌이 오는 세미나와는 달리 H3가 무엇을 의미하는지 궁금했었는데 Hello Hacking Heros라는 의미였습니다. 흥미로운 세션들이 많이 있었는데 제가 들은 세션은 다음과 같습니다.
키노트 : 하이브리드 앱의 미래, 앱스프레소 1.0 - 한기태
컨퍼런스의 시작은 유명하신 xguru님이 나오셔서 파란의 개발자블로그의 제목이기도 한 "개발자가 행복한 회사"라고 KTH를 소개하면서 시작하였습니다. 이어서 KTH의 대표이사이신 서정수님이 나오셔서 KTH의 최근 행보와 컨퍼런스를 개최하게 된 배경에 대해서 이야기 하셨습니다. 해외에서는 지금 개발자를 구하기가 쉽지 않은데 연봉이 십만불씩하는 개발자도 많이 있답니다. 최근 해외업체들과 일을 했는데 그쪽에서 워커홀릭이라고 알려진 개발자조차도 한국개발자들에 비하면 상대가 되지 않는다고 했답니다. 이러한 상황은 사회적 문제일 수도 있지만 지식을 공유하지 않는 문제의 탓도 있다고 생각하기에 KTH는 개발의 결과를 공유하기로 했고 개발블로그를 운영하고 외부강의를 하고 이렇게 컨퍼런스도 개최하게 되었다고 했습니다.(강대상에서 얘기하는게 아닌데 종이를 손에 들지 않고 얘기하셨으면 더 좋지 않았을까 생각합니다. ㅎ)

이어서 한기태님이 나오셔서 키노트를 진행되었습니다. 내용은 제목과는 좀 다르게 하이브리드앱의 미래라기 보다는 대부분 지금 하이브리드앱까지 오기까지 역사에 대한 설명이 대부분이었습니다. 모바일이 커지면서 엄청난 시장이 되었고 현재 아이폰과 안드로이드가 2강구도로 되어 있지만 장기적으로 가트너는 1강 3중체제를 예측하였습니다. 이들은 발전이 빠르고 기술이 달라서 회사나 개인이 둘다하기가 어렵기 때문에 크로스플랫폼 기술이 필요하게 되었습니다. 유일한 대안은 HTML5와 CSS3였습니다.
그동안 웹은 W3C가 HTML4이후에 감을 못잡는 사이에 브라우저 벤더들이 주축이 된 WHATWG의 주도로 HTML5가 진행되었고 현재는 크롬 OS나 WebOS, 모질라의 B2G까지 나오고 있는 상황입니다. 웹에서는 디바이스에 접근을 할 수 없기 때문에 DeviceAPI가 등장했지만 하이브리드 플랫폼마다 다른 API를 사용해서 파편화가 발생했지만 WAC만이 Waikiki표준을 만들었고 KTH의 앱스프래소도 이를 따르고 있습니다. 각 플랫폼은 사용자의 이탈을 막기 위해 락인을 하지만 WAC의 표준은 플랫폼 독립적이고 오픈표준입니다. 미들웨어인 WAC WRT를 이용하기 때문에 어디서나 가능하지만 지금은 OS가 오픈된 안드로이드에서만 가능합니다. 차후 윈도우즈폰과 바다도 지원하겠다고 이야기 했습니다.
폰갭이나 앱스프레소는 하이브리드 모바일 프레임워크입니다. 폰갭은 비표준 디바이스 API를 사용하고 통합개발환경이 없기 때문에 각 OS에 대한 지식이 어느정도 있어야 하지만 앱스프레소는 표준 Device API를 사용하고 있고 하나의 통합개발환경을 가지고 있습니다. Waikiki API 2.0을 정식으로 지원하고 있고 Wac 앱 팩키징을 지원하고 있으며 W3C위젯 1.0을 완벽하게 지원하고 있습니다. 앱스프레소는 무료로 제공하고 있는데 이를 유료화 할 계획은 없으며 저렴한 가격으로 클라우드 빌드와 푸시 알림을 제공할 예정이라고 합니다.
개인적으로 WAC에 크게 관심을 가지고 있지 않고 WAC이 iOS와 안드로이드를 누르고 장기적인 전망이 있다고도 생각치 않기 때문에 사실 Waikiki의 표준이란 것이 크게 의미가 있는가 생각하고 있습니다. 물론 저는 앱스프레소를 쓰고 있지는 않지만 현시점에서 가장 괜찮은 하이브리드 솔루션이라고 생각하고 있습니다. 이런 부분은 자사의 제품이니 마케팅 면에서 괜찮다고 하더라도 개인적으로는 그냥 세션중의 하나가 키노트로 나온건가 싶을 정도로 딱히 키노트같은 내용도 아니었고 너무 뻔한 얘기들이라 무척 지루했습니다. 2/3정도는 웹과 모바일의 뻔한 역사에 대한 얘기였던것 같습니다.(H3에서 가장 지루하지 않았나 싶네요.)
Google을 통해 살펴보는 분산 파일 시스템의 현재와 미래 - 김홍모
처음엔 분산파일 시스템에 대해서 설명했습니다. 파일을 관리하기 위해서 메타정보에 위치를 기록해서 빨리 찾을 수 있게 하지만 파일이 너무 많다면 여러대의 컴퓨터를 사용해야 하고 이를 분산파일 시스템이라고 합니다. 이미 많은 웹서비스들이 분산파일시스템을 사용하고 있는데 가장 많이 알려진 것인 GFS(Google File System)입니다. 구글의 데이터가 너무 많아서 직접 파일시스템을 만들었고 GFS는 단일 마스터 구조로 되어 있습니다.
Gmail 만들기
이어서 Gmail을 만드는 과정을 설명하였습니다. Gmail은 구글이 내놓은 최초의 사용자 정보중심의 인터랙션 웹서비스입니다.(저는 이런 측면으로는 한번도 생각해 본 적이 없어서 흥미로운 관점이었습니다.) 그래서 효율보다는 반응속도가 무척 중요합니다. Gmail을 사용하기 위해서 Google Servlet Engine과 GFS상에서 동작하는 DBMS인 BigTable을 사용합니다.
첫번째 방법은 GFS에 메일을 직접 저장하는 것입니다. 근데 메일이라 작은 파일들이 너무 많아서 두번째 방법인 Bigtable에 저장하였습니다. 빅테이블은 수많은 자료를 하나의 꾸러미로 만들어서 GFS가 처리해야 할 파일의 수를 감소시킵니다. 하지만 GFS는 단일 마스터노드 구조이기 때문에 장애가 났을 때는 위해서 이중화를 해야 합니다. 하지만 비용이 문제입니다. GFS의 복제정책은 같은 데이터를 3개씩 저장을 하므로 이중화를 하면 2배로 늘어납니다. 2011년 2월 27일에 구글의 데이터에 장애가 발생했습니다. 3월 1일에 열심히 복구중이고 데이터는 테이프에 있기 때문에 안전하다고 공지가 올라왔습니다. 실제 구글은 GFS에 추가로 테이프 백업가지 하고 있습니다. 백업을 하기 위해서는 어떤 작업이 종료되어야 백업할 수 있는데 Gmail같은 서비스는 멈추지 않고 운영되기 때문에 일반적인 전략으로는 백업할 수 없습니다. 그래서 구글은 스냅샷기능을 이용했는데 스냅샷기능을 이용하면 그 순간순간을 백업해야 하기 때문에 데이터의 량은 더욱 늘어납니다.
GFS를 뛰어넘자
GFS의 단점은 파일 수가 많고 마스터 장애에 취약하기 때문에 이중화가 반드시 필요해서 비용이 높아지게 됩니다. 이를 해결하기 위해서는 메타정보의 꾸러미를 도입하고 일정 메타정보를 묶어주고 이 메타정보는 원형으로 구성합니다. 그리고 이 메타정보 꾸러미를 서버와 짝을 맺어주면 서버의 장애가 발생했을 경우 시계방향에 있는 서버가 장애난 서버의 메타데이터꾸러미까지 처리합니다. 이를 분산해쉬테이블이라고 합니다.

그리고 복제를 하는 이유는 데이터를 잃어버리지 않기 위함인데 백업은 비용이 너무 많이 들기 때문에 데이터가 안전하면서도 비용을 줄일 수 있는 방법이 필요합니다. Erasure Code를 사용하면 자료의 일부를 잃어버려도 나머지 자료로 원본을 복구해 낼 수 있습니다. Erasure Code는 새로 만들어 진것이 아니라 인공위성과 데이터를 주고받거나 CD에서 데이터의 일부가 손실되어도 시디롬이 데이터를 복구할 수 있도록 만들어졌습니다. Erasure Code를 자세히 보면 자료를 여러개의 분할하고 분할된 자료를 Erasure Code를 사용해서 새로운 분할조각은 만듭니다. 그리고 이를 모두 저장하는데 이중에서 임의의 m개가 손실되어도 원본을 복구해 낼 수 있습니다. 때문에 Erasure Code를 사용하면 복제보다 비용을 절반으로 줄일 수 있습니다.
이렇게 GFS를 뛰어넘는 키워드는 분산메타관리 체계와 Erasure Code입니다. 구글도 여기에 비슷한 답을 내놓았는데 Colossus입니다. 아직 정식발표는 하지 않았지만 여러 컨퍼런스등에서 그 존재는 확인되고 있스빈다. KTH가 내놓은 답은 PrismFS입니다. 현재 개발중인데 PrismFS는 분산메타관리 체계를 가지고 있고 Erasure Code로 자료를 보호하고 REST API를 제공하면 모든 자료에 check-sum을 적용하고 있습니다.
분산이 점점 인기를 끌고 있지만 저는 이런 부분을 많이 알고 있지 못해서 들었습니다. 내용이 어렵지는 않았지만 이쪽에 대해서 많이 알지 못하다보니 꽤 흥미로운 세션이었습니다. 저한테는 수준이 딱 좋더군요. 단순히 분산파일시스템에 대한 설명만이 아닌 실제 구현체를 만들기 위해서 많은 고민을 한 결과에 대한 내용이라는 것을 알 수 있었고 PrismFS가 궁금해졌습니다.
하이브리드 클라우드 활용방안 및 도입전략 - 박형준
클라우드 컴퓨팅 기술 동향
2009년부터 클라우드 컴퓨팅이 주목되는 주제로 선정되었습니다. 아쉽게도 2012년에는 순위에서 좀 밀려났습니다. 클라우드 컴퓨팅은 컴퓨팅이 발전되는 가운데 웹서비스와 그리드 컴퓨팅, 네트워크 컴퓨팅, 유틸리티 컴퓨팅이 합쳐진 것입니다. Joe Weinman은 클라우드를 다음과 같이 정의했습니다.
- Common architecture : 공통된 리스스풀
- Location independent : 위치에 상관없이 서비스를 제공한다.
- Online : 온라인상으로 무중단(가급적)으로 운영
- Utility : 사용한 만큼 지불한다. 고정된 자상이 없다.
- on Demand : 급격히 사용량이 증가했을 때 요청에 따라 늘릴 수 있다.
클라우드는 배포에 따라 Private와 Public로 분류할 수 있습니다. Private는 내부 자산으로 운영하는 것이고 Public은 공개된 클라우드를 사용하기 때문에 사내 IT조직은 운영권한이 없습니다. 초기 클라우드는 기존기술에 비해 많이 부족했지만 현재는 좋아져서 많이 퍼블릭 클라우드로 옮겨가고 있습니다. 하지만 Private과 Public에는 장단점이 있기 때문에 둘을 혼합한 하이브리드를 선호하게 되었습니다.
하이브리드 클라우드 활용방안
Private 클라우드를 운영하면서 사용자가 갑자기 많아져서 이에 대처를 못하면 버스팅(Busting)이 발생하는데 이 버스팅을 퍼블릭 클라우드를 이용해서 할 수 있습니다. 사용량에 대한 계획은 기존 시스템의 사용량에 근거해서 산정하지만 대부분 잘 맞지 않습니다. 그래서 빠르게 확장(Scale Fast)하고 빠르게 수거(Fail Fast)할 수 있어야 합니다. 이는 가용서버를 사용량에 따라 빠르게 늘리고 줄일수 있어야 한다는 의미입니다. 아니면 퍼블릭 클라우드를 이용하면서 DR(Disaster Recovery)가 발생해서 퍼블릭을 이용할 수 없을 경우 Private으로 이에 대응할 수 있습니다. 물론 쉽지는 않습니다.
하이브리드 클라우드 도입 전략
사용자들은 플랫폼을 바꿀 때 전환비용에 대해서 생각합니다. 그래서 플랫폼 사업자들은 사용자들이 쉽게 벗어나지 못하도록 호환성을 막아서 락인합니다. 그래서 하이브리드를 사용할 때는 이러한 락인에 대해서 고민해야 합니다. 락인으로는 다음과 같은 기능들이 있습니다.
- Unique Feature : 플랫폼에 종속적인 특수한 기능을 사용하면 이전하기 어렵습니다.
- Contraction : 데이터 이전방법이나 사용기간등에 대한 계약등을 확인해 보아야 합니다.
Massive Data Transfer : 데이터 이전을 어떻게 할지에 대한 고민이 필요합니다.
그래서 락인은 IaaS < PaaS < SaaS 순으로 커집니다. 이러한 락인은 개발자들에 의해서 해결되기도 하는데 M/Gateway DB는 아마존의 SimpleDB와 호환되는 오픈소스 데이터베이스로 M/DB를 통해 SimpleDB의 전환비용이 낮아졌습니다. 그리고 Public은 아마존을 사용하고 Private는 Eucalyptus를 사용해서 호환성을 유지할 수 있습니다. 두번째 전략은 관리도구에 대한 고민입니다. Public과 Private을 사용하고 Public에서도 여러가지 서비스를 사용한다고 하면 이를 어떻게 관리할 것인가에 대한 고민이 필요하고 모니터링을 위한 대시보드나 권한관리를 어떻게 할지에 대한 고민이 필요합니다.
기술세션이라기 보다는 전략이나 접근방법에 대한 이야기였지만 클라우드는 직접 써보지 않았기 때문에 재미있었습니다. 말을 정말 자연스럽게 잘하시더군요. 그냥 사내 서버 아니면 클라우드 같은 식으로만 생각했었기 때문에 이러한 하이브리드에 대한 접근은 별로 생각해 보지 않았고 그로 인한 많은 이슈들에 대해서 알게 되었습니다. 마지막으로 인간의 몸에서 심장만 암에 걸리지 않는다고 하시면서 그 이유가 심장은 계속 펌프질을 하기 때문인데 IT는 계속해서 이러한 펌프질을 해야하고 우리가 모인 이유도 그 때문이라고 하셨는데 꽤 인상적이었습니다.
클라우드 컴퓨팅 AWS 글로벌 서비스 구축을 위한 선택 - 이호철
클라우드를 선택할 때는 (1) 높은 가용성(Availability) (2) 탄력적인 용량 제공(Elastic) (3) 비용 효율화(Cost-Effective)를 고려합니다. 보통 클라우드를 싸다고 생각하는 경향이 있는데 결코 싸지 않다 여기서 비용 효율화라는 것은 확작성등을 고려했을 때의 비용효율화입니다. KTH는 AWS(Amazon Web Service)를 선택했는데 이는 앞으로 pudding.to와 Friending이라는 글로벌 서비스를 오픈할 예정인데 이를 위해서는 글로벌 CDN이 필요한데 아마존을 이용하면 쉽게 할 수 있습니다. 그리고 이 서비스들은 사진을 업로드해야하는데 물리적으로 거리가 멀면 업로드 지연은 필연적이기 때문에 AWS를 지역별로 분산하면 업로드 지연을 해결할 수 있습니다.
AWS는 전세계에 6개 지역에 위치하고 있으며 각 지역당 2개의 가용존이 있습니다. 기초 서비스로 EC2와 S3, EBS, ELB, Route 53이 있고 그위에 RDBMS, Elastic Cache, SimpleDB등으로 데이터처리를 할 수 있으며 맵리듀스도 지원하고 있습니다.
- EC2 : Elastic Compute Cloud의 약자로 웹콘솔로 간단하게 가상의 컴퓨팅 환경을 생성하고 관리할 수 있습니다. 다양한 OS와 타입을 지원하고 있으며 기본적으로 3개의 네트워크 자원을 할당합니다.
- EBS : 블럭스토리지로 볼륨당 1GB에서 1TB까지 지원합니다. EC2에서 마운트해서 사용하기 때문에 EC2에 의존적입니다.
- S3 : Simple Storage Service의 약자로 데이터 스토리지입니다. 오브젝트당 1byte에서 5TB까지 사용할 수 있으며 HTTP를 사용하기 때문에 단독으로도 쓸 수 있다.
- ELB : Elastic Load Balancing의 약자로 로드밸런서입니다. 수천대의 인스턴스를 로드밸런싱할 수 있고 Sticky Session기능으로 특정 세션을 강제로 하나의 서버에 지정할 수 있습니다. 대신에 고정 IP를 지원하지 않습니다.
- Route 53 : 가장 가까운 DNS서버를 찾아서 응답속도를 높여줍니다. WRR(Weighted Round Robin)을 지원합니다.
확장성(Scalability)
스케일업은 보통 하드웨어의 성능을 높이는 것이고 스케일아웃은 수평적으로 서버의 댓수를 늘리는 것을 말합니다. EC2의 스케일업은 웹콘솔에서 별도로 지원하지 않기 때문에 스냅샷을 생성해서 더 좋은 EC2를 생성하고 기존 것은 죽이는 수동으로만 할 수 있습니다. RDS의 스케일업은 웹콘솔에서 옵션으로 처리할 수 있습니다. 대신 유지보수 일정주기에 따라 실행되며 변경시간동안에는 다운타임이 존재하게 됩니다. (즉시 실행해야 할 경우에는 옵션을 지정할 수 있습니다.)
EC2는 스케일아웃에 대해서 오토 스케일링을 지원합니다. 이것이 AWS를 선택하게 된 가장 큰 이유입니다. ELB가 EC2 인스턴스를 사용하고 Cloud Watch가 EC2의 인스턴스를 모니터링합니다. 이렇게 사용하는 것이 일반적이지만 KTH는 EC2에 2개의 EBS를 붙혀서 하나는 OS영역으로 사용하고 다른 하나는 애플리케이션의 영역으로 사용합니다.(이렇게 2개의 EBS를 사용했을 때의 장점은 설명하지 않으셨는데 궁금하더군요.) 오토스케일링을 위해서 인스턴스의 타입이나 이미지를 선택하는 Launch config를 생성하고 오토스케일링 그룹에서 최대로 생성할 인스턴스 갯수와 최소로 생성할 인스턴스의 갯수를 지정할 수 있습니다. 그리고 Trigger를 통해서 스케일아웃을 하는 조건을 설정할 수 있습니다. CPU나 특정시간을 지정할 수 있으며 증가/감소할 인스턴스의 갯수도 지정할 수 있습니다.
RDS의 스케일아웃은 오토스케일링은 지원되지 않고 마스터-슬레이브 구조의 리플리케이션만 지원합니다. 그리고 이때 슬레이브는 여러 지역으로 분산시킬 수 있습니다.
고가용성(High Availability)
ELB는 수천대의 EC2를 로드밸런싱합니다. 여기서 EC2를 오토스케일링 하는 구조로 만들어야 하고 같은 지역에 있으므로 가용성을 높이기 위해서 Multi-AZ구조로 만들어합니다. 이렇게 만들면 데이터베이스가 병목지점이 될 수 있으므로 디비를 마스터 슬레이브 구조로 바꿔서 구성했습니다.
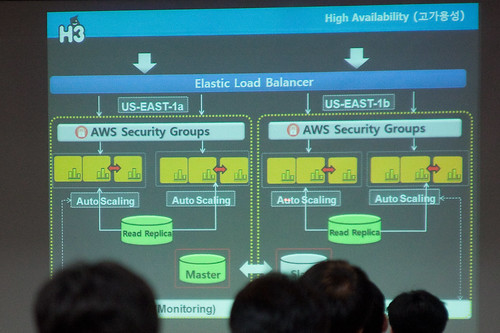
성능(Performance)
성능최적화를 위해서 CloudFront를 선택했습니다. 사용자가 S3에 파일을 업로드 하면 CloudFront 네트워크를 통해서 사용자가 접속하고 CloudFront에 파일이 없으면 S3에서 가져와서 캐싱을 하기 때문에 이후의 사용자는 캐싱된 파일로 제공합니다. CloudFront는 다운로드뿐만 아니라 스트리밍도 제공하고 있습니다. CloudFront는 저렴하기 때문에 한달에 1G정도를 사용해도 50만원정도밖에 하지 않습니다.
그리고 디비로 다 커버를 못하는 부분을 위해서 MemCached기반인 Elastic Cache를 사용했습니다. 캐시를 통해서 디비부하를 줄일 수 있는데 현재는 미동부지역만 지원하고 있습니다. 그 외의 지역에서는 EC2상에 MemCached나 Redis를 설치해서 사용할 수 있습니다.
그 밖의 팁
이번에 AWS를 구성하면서 얻게 된 몇가지 팁을 알려주었습니다. 파일을 업로드할 때 물리적인 거리로 인해서 생기는 Upload Latency는 어떤 것으로도 해결할 수 없습니다. 그래서 KTH에서는 각 지역마다 업로드 서버그룹을 구성하여 사용자는 가장 가까운 서버에 업로드를 하고 서버에서 메인서버가 있는 미동부로 전송하도록 만들었습니다. 그리고 현재는 개발단계라 크게 집중하고 있지는 않지만 서버에 대한 접근제어는 오픈시에는 매우 중요한 부분입니다. 웹서버는 80/443포트만 개방하고 아마존의 Security그룹으로 들어갈 수 있는 통로는 오직 Gateway서버를 통해서만 접근할 수 있도록 구성하였습니다. 그래서 관리자나 개발자는 게이트웨이 서버를 통해 Security그룹의 안쪽으로 접근할 수 있습니다.
아마존 클라우드에 대한 책을 보기도 했지만 실제로 써보지 않기도 했고 워낙 많은 서비스가 있기 때문에 잘 몰랐는데 이번 세션을 통해서 대부분의 서비스의 용도를 구체적으로 설명해 주어 좋았습니다. 무엇보다 단순히 서비스에 대한 설명만이 아닌 실제로 KTH가 아마존으로 서비스를 구성하기 위해서 오랫동안 고민해 온 것의 결과로써의 서비스 소개였기 때문에 어느 부분에 어떤 서비스가 필요하고 왜 필요한지 알 수 있었습니다.
이 포스팅은 H3 Developers Conference 2011 후기 #2로 이어집니다.

딱 하나 말씀드리고 싶은점은 H3의 뜻이 적어주신게 아니라는거.. ^^;
Hello Hacking Heros 와 Happy Hacking Hero 는 올해 컨퍼런스용으로 사용한 말장난입니다.
내년 H3 는 그게 아닐수도 있습니다 ;)
앗 그렇군요.. 이런 유쾌한 장난 좋아요 ㅎㅎㅎㅎ
해피해킹이라고도 어디 써있지 않았었나요? 해피해킹이라고 했다가 주위사람들한테 키보드나고 잔소리 들었었는데요 ㅋㅋ
암튼 실제로 인사드려서 반가웠습니다. ㅎㅎ 다음에 뵈면 인사드릴께요 ㅎ
이런 세미나도 있다니~~ 좋네요^^
반응형웹과 html5 앞으로 변화되는 웹환경이 기대됩니다.
그만큼 열심히 해야겠어용~~
잘 보고 갑니다
저도 오랜만에 즐거운 세미나였네요..
볼게 너무 많아요 ㅎ