

(원래는 좀더 자극적인 제목을 썼다가 시간이 좀 지나고 그러다 보니 약간 노말(?)한 제목으로 바꾸었다. 낮에 포스팅 할라다가 바빠서.. ㅡ..ㅡ)
오늘 내가 자주가는 사이트중 하나인 SLRClub에 갔더니 엠파스 관련 글이 많이 올라와있었다. 먼가 했더니 자유게시판(다른 게시판도 되는지는 잘...)의 글이 엠파스에서 검색이 된다는 것이었다

대부분 아는 사항이겠지만 혹시 잘 모를 분들을 위해(나도 잘 모른다.) 검색에 대해서 조금 얘기를 하자면 검색사이트를 제공하는 곳에서는 크롤러라는 게 있다. 검색봇이라고도 한다.(물론 물리적으로 존재하는 건 아니다. ㅡ..ㅡ) 하여튼간 이 크롤러가 웹페이지를 미친듯이 돌아다니면서 웹페이지의 정보를 가져오고 그걸 분석해서 제공하는게 우리가 쓰는 검색엔진이다. 그래서 이 크롤러의 성능에 따라도 많이 달라지고(요즘은 다들 잘 긁어오는듯...) 구글처럼 가져온 데이터를 어떻게 분석하느냐에 따라 검색의 결과가 많이 달라지게 된다.
나두 크롤러의 내부구조같은건 잘 모르지만 일단 이녀석은 우리가 들어갈 수 있는 대부분의 웹사이트에는 다 들어갈 수 있다. 하지만 당연히 웹페이지란건 다 html소스이므로 이걸 분석해서 긁어오는 것이다. 실제 기술 구현을 해본건 아니지만 html과 웹이란 특성을 생각했을때 긁어오는 것 자체는 막을 방법이 없다. 그냥 와서 긁으면 되니까...
하지만 웹이란건 오픈이 일반적이지만 모두 그런건 아니다. 여자친구랑 비밀얘기를 하고 싶을 수도 있고 개인 일기장으로 사용할 수도 있다. 개인 공간이라고 생각하고 비밀스런 내용을 적었는데 네이버에서 검색한방에 나와버린다면 참으로 난감한 일이 아닐 수 없다. 그러면 누가 웹을 맘놓고 쓰겠는가.....
그래서 robots.txt라는 게 있다. 파일명을 보듯이 알겠지만 그냥 텍스트 파일이다. 이게 표준안이고 사이트도 있다.
아까 말한 크롤러가 사이트를 긁어갈라고 웹사이트에 오면 일단 루트경로에 robots.txt파일을 까본다. 그러면 표준안에 맞게 내용을 어디는 긁어가도 되고 어디는 긁어가면 안되는 지가 써있다. 그걸 보고 허용된 만큼 수집을 해가는 것이다.
물론 표준안이기 때문에 법적 구속력은 없기 때문에 크롤러가 이 표준안을 따르지 않고 수집하려면 할 수 있다는 얘긴데 이게 이제 막 제정된 표준도 아니고 개인적으로 만든 검색엔진도 아니고 상업적으로 운영되는 크롤러라면 당연히 준수해 주어야 할 상도같은 거다. 그리고 이걸 지키지 않으면 비난을 면치 못할 꺼라고 생각했다.
근데 그런 일이 벌어졌다. 그것도 어디 듣도 보도 못한 곳도 아니고 한국 검색사이트하면 5-6번만에 이름 나올만한 엠파스에서.....
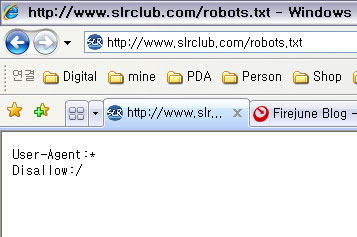
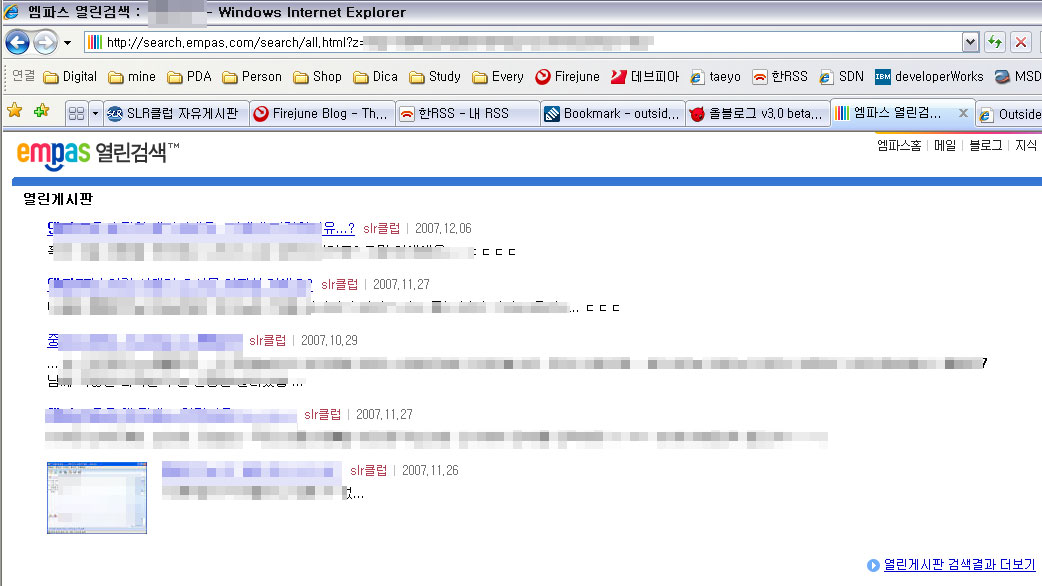
엠파스에 가서 좀 이름 유명한 닉으로 검색하면 열린게시판이란 부분에서 마구 쏟아지고 친절하게 썸네일까지 제공해주고 있다. 물론 누르면 SLRClub으로 간다. 자유게시판 같은 부분은 로그인을 안해도 볼 수가 있는 곳이기 때문에 뭐가 문제냐고 생각할지도 모르지만 이건 솔직히 개념을 상실한 거라고까지 생각이 된다. 더군다나 얘기를 듣자하니 이문제로 여러번 항의를 했는데도 고쳐지지가 않는다고 한다.
명시적으로 수집을 거부했는데 그것도 지키지 않다니.... SLR클럽같이 좀 크고 공통단어로 나오는 결과가 많기 때문에 확인이 가능했지만 공개하기를 거부한 어떤 내용을 엠파스가 검색결과로 보여주고 있는지는 모를일이다.
일단 현재로선 많은 항의가 들어와서인지 (일시적인지 몰라도) SLR클럽의 글들은 오후늦게부터는 검색결과에 나타나지 않고 있다. 물론 그에대해 특별히 엠파스의 입장 표명은 없었던듯 하다.(있

흠.. 전 햄처럼 SLR 을 디카 지식성이 아닌 넋두리라고 해야되나.. 걍 자유글 보는 용도로 자주 봤었네용.. 햄도 엄청 오래되었군용.. ㅎㅎ.. 다만 저런 접근에 대한 부분이 있었다는걸 첨 알았네용..