

오픈소스 모니터링 시스템 Prometheus #1
기능 좋고 사용하기 편한 New Relic을 좋아하고 잘 쓰고 있지만, 기본적인(이것도 엄청 풍부하지만) 기능 이상을 쓰려면 가격이 아주 비싼 편이다. New Relic은 좋지만 가격 정책은 참 별로라고 생각하고 있는데 비싸기 때문이라기보다 유료라도 쓰기가 불편하다. Pro를 쓰려면 한 달에 $140 정도를 내야 하는데 New Relic은 자동 모니터링이므로 서버 10대 있을 경우 한대만 유료로 APM을 적용하는 것이 불가능하다. 10대에 다 유료로 하면 $1,400이나 나오므로 현실상 불가능하고 유료로 했다는 이유로 다른 서버의 모니터링을 끄거나 하는 불편함이 생기고 APM이나 모니터링은 응급 대응용인데 $140이 부담스러운 것도 사실이다. New Relic을 유료로 쓰는 회사가 얼마나 있는지 의심스러울 정도고 서버가 늘어갈수록 부담은 더 커진다. 그리고 요즘 많이 쓰는 Docker 같은 컨테이너를 모니터링 하려면 무료로는 사용할 수가 없다.
그러다 보니 사용 가능한 모니터링 도구를 찾기 시작했고 anarcher님의 추천으로 Prometheus를 살펴보기 시작했다.
Prometheus
모니터링이나 APM 도구를 많이 써보고 잘 아는 것은 아니지만 Prometheus는 다른 모니터링 도구와는 좀 다른 특성을 가진 도구이다.
From metrics to insight라는 문구가 인상적이다. 주변의 추천도 있고 최근에 관심을 가지고 보고 있어서 그런지 요즘 주목을 많이 받는 것으로 보인다.
Prometheus는 오픈소스이고 Apache 2 라이센스로 공개되어 있어서 유료 걱정 없이 사용할 수 있다.
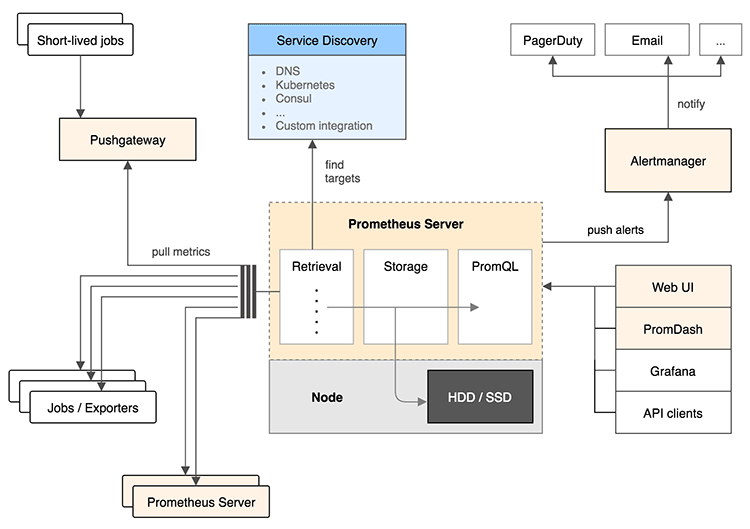
Prometheus의 구조는 Prometheus 저장소에 나와 있는 아키텍처를 보면 좀 이해하기가 쉽다. 처음에는 꽤 복잡해 보였지만 동작 방식을 이해하면 이 그림을 이해할 수 있게 된다. 다른 모니터링 도구와 가장 다른 점은 대부분의 모니터링 도구가 Push 방식 즉, 각 서버에 클라이언트를 설치하고 이 클라이언트가 메트릭 데이터를 수집해서 서버로 보내면 서버가 모니터링 상태를 보여주는 방식인데 반해서 Prometheus는 Pull 방식이다. 그래서 서버가 각 클라이언트를 알고 있어야 하는게 아니라 서버에 클라이언트가 떠 있으면 서버가 주기적으로 클라이언트에 접속해서 데이터를 가져오는 방식이다.
몇 가지 특징을 짚고 넘어갈 수 있는데 구성을 크게 나누면 Exporter, Prometheus Server, Grafana, Alertmanager로 나눌 수 있다. 뒤에서 실제로 사용해 보면 더 이해가 가겠지만, 사전에 알아두어야 할 특징을 정리해 보자.
- Exporter는 모니터링 대상의 Metric 데이터를 수집하고 Prometheus가 접속했을 때 정보를 알려주는 역할을 한다. 호스트 서버의 CPU, Memory 등을 수집하는 node-exporter도 있고 nginx의 데이터를 수집하는 nginx-exporter도 있다. Exporter를 실행하면 데이터를 수집하는 동시에 HTTP 엔드포인트를 열어서(기본은 9100 포트) Prometheus 서버가 데이터를 수집해 갈 수 있도록 한다. 이 말은 웹 브라우저 등에서 해당 HTTP 엔드포인트에 접속하면 Metric의 내용을 볼 수 있다는 의미이다.
- Exporter를 쓰기 어려운 배치잡 등은 Push gateway를 사용하면 된다. 내가 보기에는 Push gateway도 결국 Exporter의 일종이라고 생각된다.
- 웹 애플리케이션 서버 같은 경우의 Metric은 클라이언트 라이브러리를 이용해서 Metric을 만든 후 커스텀 Exporter를 사용할 수 있다.
- Prometheus Server는 Expoter가 열어놓은 HTTP 엔드포인트에 접속해서 Metric을 수집한다. 그래서 Pull 방식이라고 부른다.
- Prometheus Server에 Grafana를 연동해서 대시보드 등의 시각화를 한다.
- 알림을 받을 규칙을 만들어서 Alert Manager로 보내면 Alert Manager가 규칙에 따라 알림을 보낸다.
내가 그랬듯이 이렇게 특징을 봐도 하나도 이해가 안 갈 텐데 실제로 사용을 해보면 훨씬 쉽게 이해가 되므로 하나씩 살펴보자.
Prometheus Server
Prometheus 서버는 다운로드 페이지에서 OS 별로 다운로드 받을 수 있고 설치 문서를 보면 Docker 이미지로도 제공하고 있다. 편한 방식을 사용하면 되는데 여기서는 설명을 위해서 직접 다운로드를 받아서 사용해 보자. 현재 버전은 1.4.1이다.
다운받아서 압축을 풀면 prometheus 파일과 예시 설정 파일인 prometheus.yml파일이 존재하는데 이 파일을 이용해서 다음과 같이 실행하면 된다.
1$ ./prometheus -config.file=prometheus.yml
2INFO[0000] Starting prometheus (version=1.4.1, branch=master, revision=2a89e8733f240d3cd57a6520b52c36ac4744ce12) source=main.go:77
3INFO[0000] Build context (go=go1.7.3, user=root@e685d23d8809, date=20161128-09:59:22) source=main.go:78
4INFO[0000] Loading configuration file prometheus.yml source=main.go:250
5INFO[0000] Loading series map and head chunks... source=storage.go:354
6INFO[0000] 0 series loaded. source=storage.go:359
7INFO[0000] Starting target manager... source=targetmanager.go:63
8INFO[0000] Listening on :9090 source=web.go:248
9090포트로 Prometheus 서버가 실행된 것을 볼 수 있다.
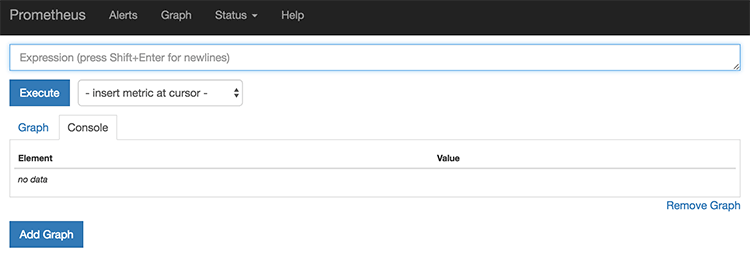
서버를 띄운 서버가 52.192.141.64라고 한다면 http://52.192.141.64:9090으로 접속하면 http://52.192.141.64:9090/graph로 리다이렉트가 되는데 위와 같은 화면을 볼 수 있다. 여기서 간단하게 수집된 데이터를 볼 수 있다. 맨 위의 입력 칸은 데이터 조회를 위한 평가식을 입력하는 곳인데 평가식은 뒤에서 좀 더 자세히 설명하고 여기서는 셀렉트박스에서 원하는 값을 선택하고 Execute를 누르면 된다.
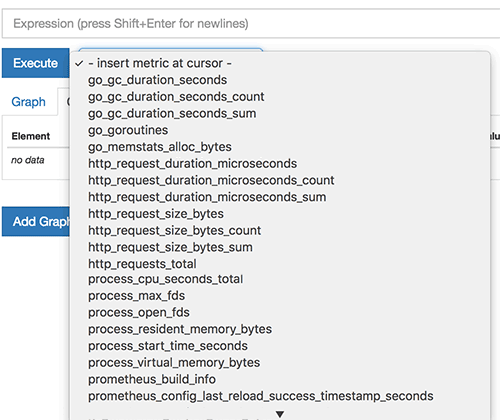
셀렉트박스를 열면 수집하고 있는 매트릭의 목록을 볼 수 있다. 원하는 매트릭을 선택하고 Execute를 누르면 하단에서 그래프를 볼 수 있다.
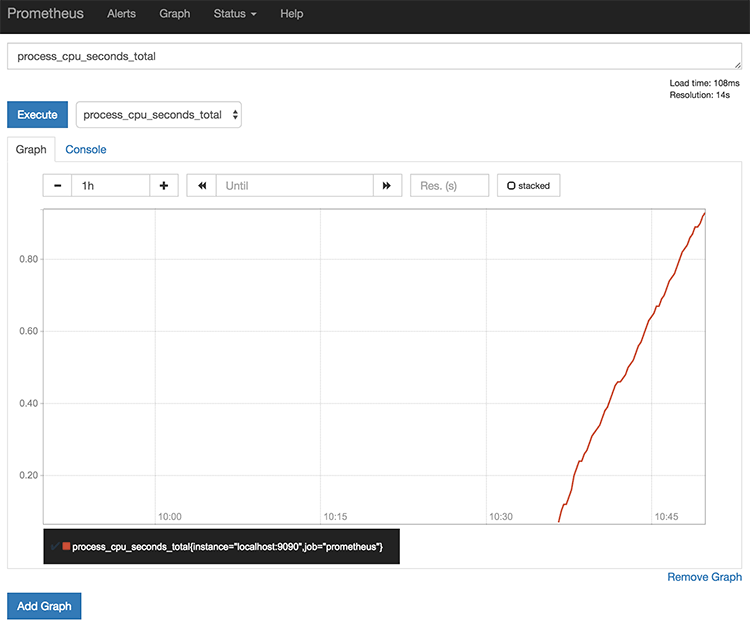
이 화면을 간단한 대시보드처럼 사용할 수도 있다.
prometheus.yml
이제 Prometheus 서버를 띄울 때 사용한 설정 파일인 prometheus.yml를 살펴보자.
1# 전역 설정
2global:
3 scrape_interval: 15s # 15초마다 매트릭을 수집한다. 기본은 1분.
4 evaluation_interval: 15s # 15초마다 규칙을 평가한다. 기본은 1분.
5
6 # 외부 시스템에 표시할 이 서버의 레이블
7 external_labels:
8 monitor: 'codelab-monitor'
9
10# 규칙을 로딩하고 'evaluation_interval' 설정에 따라 정기적으로 평가한다.
11rule_files:
12 # - "first.rules"
13 # - "second.rules"
14
15# 매트릭을 수집할 엔드포인드로 여기선 Prometheus 서버 자신을 가리킨다.
16scrape_configs:
17 # 이 설정에서 수집한 타임시리즈에 `job=<job_name>`으로 잡의 이름을 설정한다.
18 - job_name: 'prometheus'
19
20 # metrics_path의 기본 경로는 '/metrics'이고 scheme의 기본값은 `http`다
21
22 static_configs:
23 - targets: ['localhost:9090']
기본으로 제공된 파일에서 주석으로 된 설명만 추가로 달아놨다.
global부분은 매트릭 수집을 위한 전역설정 값이다. 프로메테우스 서버를 프로메테우스 서버에 연결하거나 Alert Manager 등에서 이 서버의 데이터를 가져갈 수 있는데 그때 구분할 수 있도록external_labes로 이름을 지정할 수 있다.rule_files는 Alert 규칙 등 필요한 규칙을 작성해서 사용할 수 있는데 현재는 아무런 규칙을 지정하지 않았다.scrape_configs가 실제 수집 대상을 지정하는 설정이다. 여기서는prometheus라는 이름으로 한 개만 설정했다. 이는 여러 대상을 설정할 수 있다는 것이고targets가 배열로 지정하므로 서버군을 모두 여기 지정할 수 있다.targets를localhost:9090으로 설정했는데 이는 Prometheus 서버 자신을 가리킨다.targets에 지정하는 것은 Prometheus 서버가 접근해서 데이터를 가져올 Exporter의 HTTP 엔드포인트이다. 그래서localhost:9090으로 지정을 하면 기본값인metrics_path를 이용해서localhost:9090/metrics에 접근해서 데이터를 가져온다. 이는 Prometheus 서버가 매트릭을 수집하는 서버인 동시에 매트릭을 노출하는 Exporter이기도 하다는 의미이다.- 이 예시에서는
scrapte_configs를 수동으로 지정했는데 실제 사용한다면 이런 식으로 모니터링할 서버를 수동으로 관리할 수는 없다. CONFIGURATION 문서를 보면 모니터링 대상을 Consul, DNS 기반의 서비스 디스커버리를 이용해서 동적으로 설정할 수 있다.
웹 브라우저에서 http://52.192.141.64:9090/metrics에 접근하면 Exporter가 노출한 매트릭 데이터를 볼 수 있다.

Prometheus는 클러스터링 기능이 없다. 한대의 Prometheus 서버로 수천 대의 서버를 다 모니터링할 수는 없는데 내가 아는 선에서는 현재 Prometheus 서버를 Prometheus 서버에 연결해서 사용하는 방식으로 확장하는 것으로 알고 있다.(아직 구축해 본 것은 아니라서...) 즉, 100대를 수집하는 Prometheus 서버를 두고 이 서버가 수집한 데이터를 다시 수집하는 Prometheus 서버를 또 뒤에 둔다는 것이다.
Exporter
간단히 Prometheus 서버를 살펴봤으므로 이제 매트릭을 제공하는 Exporter를 살펴봐야 한다. 위에도 얘기했듯이 Exporter는 필요한 매트릭을 수집하고 이를 HTTP 엔트포인트로 Prometheus에 노출하는 역할을 한다. 문서를 보면 Consul exporter, MySQL server exporter, RabbitMQ exporter, HAProxy exporter, Docker Hub exporter, AWS CloudWatch exporter 등 다양한 Exporter를 지원하고 있다. 필요한 곳에 Exporter를 설정해서 Prometheus가 이를 수집하도록 하면 된다.
Exporter를 다 살펴볼 수는 없으므로 서버의 CPU, 메모리, 디스크 등의 상태를 모니터링하는 Node exporter를 사용해 보자. Node exporter는 Docker로도 사용할 수 있으므로로 여기서는 간단히 Docker로 띄워보자.
1$ docker pull prom/node-exporter
2Using default tag: latest
3latest: Pulling from prom/node-exporter
48ddc19f16526: Pull complete
5a3ed95caeb02: Pull complete
68279f336cdd3: Pull complete
781998f54d5a6: Pull complete
8Digest: sha256:5655be43374133b9ad72b8761b5661762acf513126c0f147ce1902ac52230f52
9Status: Downloaded newer image for prom/node-exporter:latest
10
11$ docker run -d -p 9100:9100 --net="host" prom/node-exporter
12cf70bc7297369012ce15683352cf1246c89d1410f44d80758fd69ef58123c838
이 서버의 IP가 52.69.72.174라고 한다면 9100포트로 Node exporter를 띄웠으므로 http://52.69.72.174:9100/metrics에 접속을 하면 다음과 같이 Exporter가 수집한 매트릭 정보를 볼 수 있다.
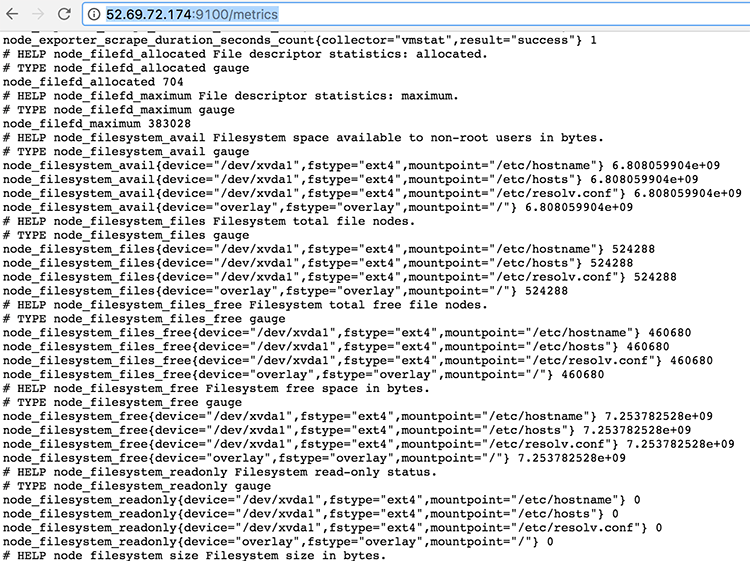
이제 모니터링할 서버가 생겼으므로 앞에서 본 prometheus.yml에서 이 서버를 모니터링하도록 추가해 보자.
1scrape_configs:
2 - job_name: 'prometheus'
3
4 static_configs:
5 - targets: ['localhost:9090']
6 - job_name: 'test-server'
7
8 scrape_interval: 10s
9
10 static_configs:
11 - targets: ['52.69.72.174:9100']
기존에 있던 prometheus 잡외에 test-server라는 이름으로 새로운 잡을 추가하고 위에서 설정한 Node-exporter를 바라보도록 했다.
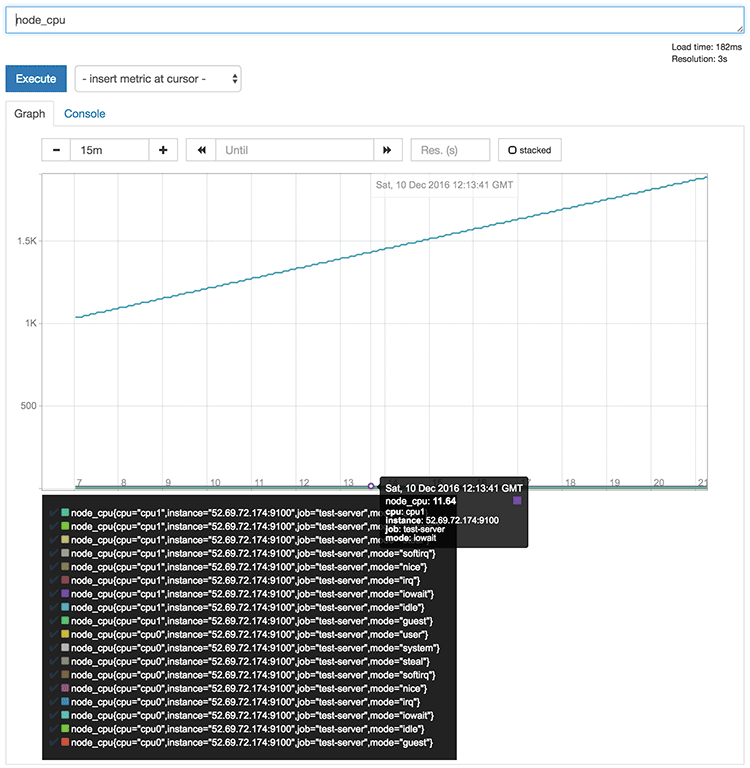
이제 서버를 다시 띄우고 모니터링을 하면 앞에서 본 Prometheus 서버 페이지인 http://52.192.141.64:9090/graph에서 test-server에 대한 매트릭정보를 볼 수 있다.
표현식 언어
Prometheus에서는 수집한 매트릭 데이터를 조회할 수 있는 함수형 표현식 언어를 제공하고 있다. 이 표현식 언어로 매트릭 데이터를 실시간으로 조회할 수 있고 위에서 셀렉트 박스로 특정 매트릭을 선택해서 데이터나 그래프를 본 것도 이 표현식 언어를 사용한 것이다.
- 앞에서 조회해 본
process_cpu_seconds_total,node_cpu,http_requests_total등을 인스턴스 벡터라고 부른다. 이 인스턴스 벡터로 쿼리를 할 수 있다. - 인스턴스 벡터 뒤에
{ }로 레이블을 지정하면 필터링을 할 수 있는데http_requests_total{job="prometheus",group="canary"}와 같이 사용한다. 이렇게 하면http_requests_total에서 job 이름이 prometheus이고 group은 canary인 정보만 조회한다.- 레이블에서는
=,!=,=~,!~같은 논리연산자를 사용할 수 있고 여기서~는 정규표현식 비교를 의미한다. 그래서http_requests_total{environment=~"staging|testing|development",method!="GET"}와 같이 사용할 수 있다.
- 레이블에서는
- 인스턴스 벡터 뒤에 레인지 벡터라고 부르는
[]를 사용할 수 있다.http_requests_total{job="prometheus"}[5m]라고 하면 최근 5분의 값을 조회한다. node_cpu offset 10m처럼 특정 시간의 값을 조회하는 오프셋 모디파이어를 사용할 수 있다.
이 글은 오픈소스 모니터링 시스템 Prometheus #2로 이어진다.
좋아요ㅎㅎㅎ 한번 써봐야겠네요!
써보고 알려줘.. ㅎㅎ 명수형이 프로메테우스 고수임.
되지 않는 영어로 번역기 돌려가면서 테스트 및 정리하고 있는데 더욱더 디테일하게 정리해 주셨네요. 정말 감사합니다. 실례가 안된다면 가져가고 싶습니다. 문제 발생 시 알려주시면 자삭 하겠습니다!
CCL하에 배포하고 있습니다. 출처를 밝혀주시고 비영리로 운영하시면 됩니다. 어디로 퍼갔는지 알려주시면 감사하겠습니다.
http://hyunki1019.tistory.com/127 로 가져갑니다 :) 좋은 정보 정말 감사합니다. 문제 있으시면 언제든지 알려주세요. 당분간 해당 댓글 모니터링 하고 있겠습니다.
자세한 설명 감사합니다^_^)//