

이 글은 오픈소스 모니터링 시스템 Prometheus #1에서 이어진 글이다.
Grafana
Prometheus가 간단한 그래프를 보여주지만, 실제 모니터링 환경에서는 좀 더 전문화된 시각화 도구가 필요하다. Prometheus에서 원래는 PromDash라는 시각화 프로젝트를 하고 있었지만, 지금은 폐기하고 Grafana를 쓰라고 권장하고 있다. Prometheus 문서 Grafana 2.5.0을 기준으로 설명하고 있지만, 최신 버전인 v4.0.2를 사용해 보자. Grafana의 설치 문서대로 Ubuntu 서버에서는 다음과 같이 설치한 뒤에 Grafana를 시작할 수 있다.
$ wget https://grafanarel.s3.amazonaws.com/builds/grafana_4.0.2-1481203731_amd64.deb
$ sudo apt-get install -y adduser libfontconfig
$ sudo dpkg -i grafana_4.0.2-1481203731_amd64.deb
$ sudo service grafana-server start
설치한 서버의 IP가 52.192.141.64라고 하면(여기선 위의 Prometheus 서버와 같은 서버이다.) http://52.192.141.64:3000로 접속하면 Grafana의 화면을 볼 수 있다.

기본 계정은 admin/admin으로 로그인하면 된다. Grafana의 데이터소스로 Prometheus를 추가해야 하는데 Grafana 2.5.0 이후부터는 기본으로 Prometheus 데이터소스가 포함되어 있다.
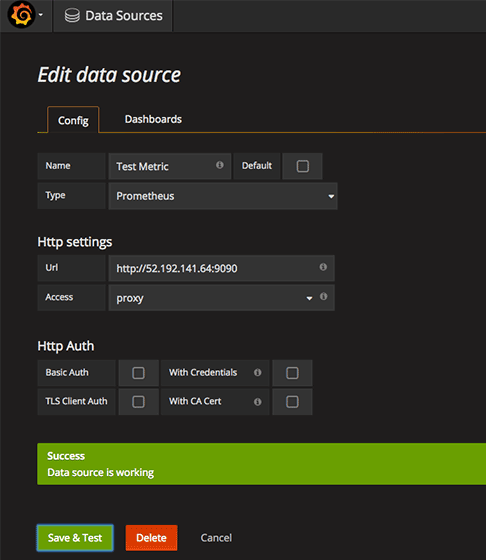
데이터소스를 추가하면서 Prometheus의 서버를 지정해서 추가하면 된다.
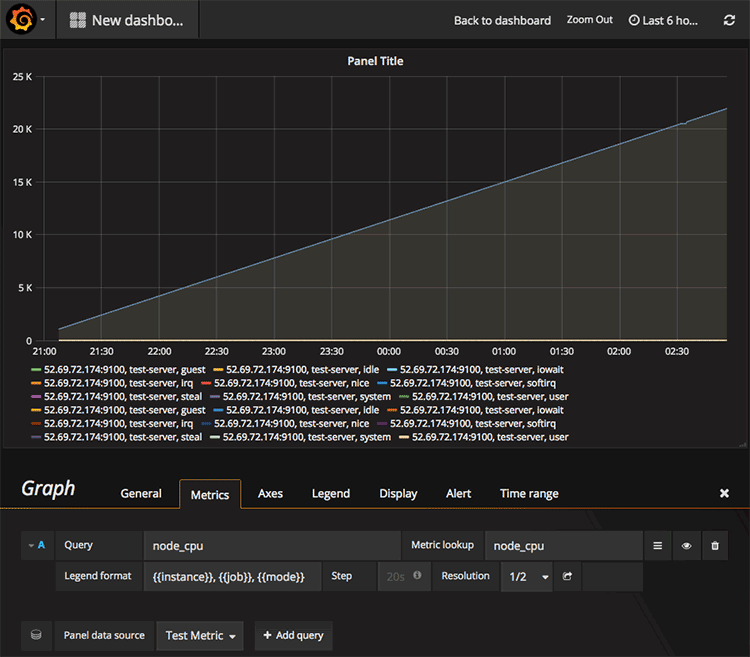
새로운 대시보드에서 그래프를 추가할 때 위에서 추가한 데이터소스를 지정하면 된다. 이제 Metric loopup에서 사용할 수 있는 매트릭을 검색할 수 있고 Query 부분에는 앞에서 살펴본 표현식 질의문을 그대로 사용하면 된다. Legend format은 레전드에 표시할 형식을 지정하면 되는데 레이블에 지정된 값을 {{ }}로 사용하면 그 값이 표시된다.
Alertmanager
Prometheus에서는 알림 시스템이 분리되어 있다. 서버 매트릭에 어떤 문제가 있거나 했을 때 기준을 정해두고 이를 Alertmanager에서 관리해서 개발자가 알림을 받을 수 있도록 하고 있다. 최근 Grafana v4.0에 Alert 기능이 들어가서 Prometheus의 Alertmanager가 어떻게 될지는 좀 더 두고 봐야 할 것 같지만 일단 Alertmanager를 살펴보자. Alertmanager도 꽤 잘 만들어졌다고 생각하고 있는데 다음과 같은 특징이 있다.
- Grouping: 알림을 그룹으로 묶어서 하나의 알림으로 보낼 수 있다. 클러스터의 다수 서버에서 장애가 생겼을 경우 그룹을 묶어주면 알림을 여러 개 받지 않고 하나의 알림만 받을 수 있다.
- Inhibition: 특정 알림이 이미 발생한 경우 다른 알림을 중단할 수 있다. 예를 들어 서버나 클러스터 자체에 장애가 생기면 수많은 알림이 발생할 수 있는데 여기에 조건을 주어 다른 알림은 보내지 않도록 설정할 수 있다.
- Silences: matcher로 조건을 주어서 조건에 맞는 경우 일정 시간 동안 알림을 멈출 수 있다.
다운로드 페이지에서 Alertmanager를 다운로드 받아서 압축을 풀면 샘플 설정 파일이 들어 있다. 설정 파일이 복잡하므로 다음처럼 간단한 config.yml을 보자.
global:
slack_api_url: 'https://hooks.slack.com/services/xxxxxx'
route:
receiver: 'slack-notifications'
group_by: ['alertname', 'cluster']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
routes:
- receiver: 'slack-notifications'
group_wait: 10s
match_re:
service: mysql|cassandra
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#monitor'
slack_api_url은 슬랙으로 알림을 보낼 API URL이다.route에서 라우팅 트리를 설정한다. 알림이 온 경우 이 라우팅 트리에서 자식 트리를 좇아가면서 조건에 맞는 라우팅을 찾아서 알림을 보내게 된다.
receiver는 알림을 받을 대상으로 하단의receivers에 상세 설정이 있다.group_by는 이 알람에 그룹명을 부여한다.group_wait는 해당 그룹에 알림이 왔을 때 알림을 보내기 전의 대기 시간이다.group_interval은 최초 알림이 발생하고 해당 그룹에 또 알림이 왔을 때 알림을 보내기 전에 대기할 시간이다.repeat_interval은 같은 알림이 왔을 때 또 알림을 보낼 시간이다.match_re는 정규표현식으로 조건에 맞는 알림을 지정할 수 있다. 여기서는service레이블이mysql이나cassandra인 알림이 이 라우팅에 걸린다.
receivers는 알림을 보낼 곳의 목록이다.
좀 더 자세한 설정은 문서를 참고하면 된다. 이 설정 파일로 alertmanager를 실행하자.
$ ./alertmanager -config.file=config.yml
INFO[0000] Starting alertmanager (version=0.5.1, branch=master, revision=0ea1cac51e6a620ec09d053f0484b97932b5c902) source=main.go:101
INFO[0000] Build context (go=go1.7.3, user=root@fb407787b8bf, date=20161125-08:14:40) source=main.go:102
INFO[0000] Loading configuration file file=config.yml source=main.go:195
INFO[0000] Listening on :9093 source=main.go:250
알림 규칙
alertmanager가 알림을 보내는 규칙은 Prometheus에서 설정한다. 처음에는 이 부분이 좀 헷갈렸는데 매트릭을 수집하고 관리하는 Prometheus 서버가 알림 조건을 만났을 때 alertmanager에 알림을 보내게 되고 alertmanager가 이를 받아서 어디에 알림을 보낼지 등을 관리하는 방식이다. 실제로 테스트를 해보면 Alertmanager가 별도로 있으므로 다수의 Prometheus 서버에 대한 알림도 한곳에서 관리할 수 있고 알림 간의 상관관계도 관리할 수 있어서 괜찮은 접근이라는 생각이 든다.
ALERT <alert name>
IF <expression>
[ FOR <duration> ]
[ LABELS <label set> ]
[ ANNOTATIONS <label set> ]
알림 규칙은 위와 같은 형태로 작성한다. 이 형태에 따라 예시로 작성하면 다음과 같은 형태가 된다.
ALERT InstanceDown
IF up == 0
FOR 30s
LABELS { severity = "page" }
ANNOTATIONS {
summary = "Instance {{ $labels.instance }} down",
description = "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 30 seconds.",
}
이 규칙은 서버의 exporter가 떠 있는지를 검사하는 up이 0이면 즉, 꺼져있으면 InstanceDown이라는 알림을 보내는 규칙이다. 이 파일을 alert.rules라는 이름으로 저장하고 Prometheus의 설정 파일인 prometheus.yml에 지정하면 된다.
rule_files:
- "alert.rules"
설정을 추가하고 다시 Prometheus 서버를 띄우는데 옵션으로 alertmanager 서버를 다음과 같이 지정해 주어야 한다.
$ ./prometheus -config.file=prometheus.yml -alertmanager.url=http://52.192.141.64:9093
서버의 up에 알림을 추가했으므로 앞에서 설정한 Node exporter를 종료하면 알림이 발생하게 된다.
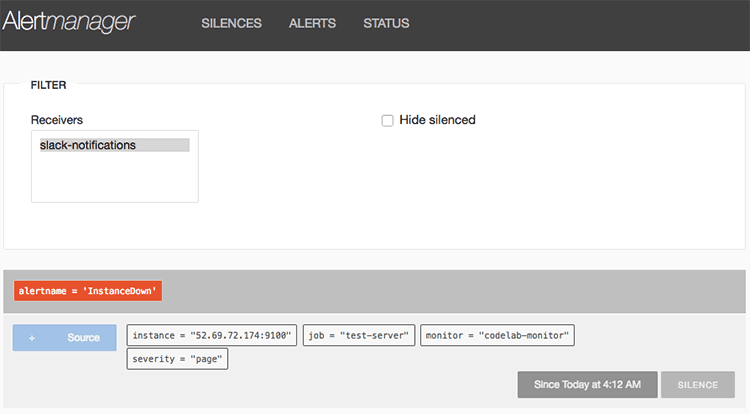
http://52.192.141.64:9093에 접속해서 Alermanger의 관리 화면을 보면 발생한 알림의 히스토리가 나타난 것을 볼 수 있고 다음과 같이 Slack 채널에 알림 메시지가 제대로 도착한 것을 볼 수 있다.

처음 Prometheus에 대해서 들었을 때는 Pull 방식으로 모니터링을 한다는 것이 잘 이해가 되지 않았다. 실제로 모니터링 환경을 구축하고 사용해 보면 또 여러 가지 문제에 부딪히고 여러 느낌이 오겠지만, 테스트로 사용해본 느낌은 꽤 괜찮다고 느껴진다. Prometheus는 구글이 내부에서 사용하는 Borgmon 모니터링 시스템에서 영감을 받아서 만든 것으로 알려져 있는데 기존 모니터링 같은 경우 각 서버에서 클라이언트를 실행하고 상황에 따라 이를 업데이트해주는 등의 귀찮은 작업등이 있는데 HTTP 엔드포인트로 수집하고 Prometheus 서버에서 중앙관리를 하는 접근이 꽤 좋다고 느껴졌다.

혹시 Prometheus도 Cacti 같은 모니터링 툴 처럼 모든 장비를 다 볼 수 있는 식으로 화면을 띄울 수 있나요? 도입하려고 하는데 모든 시스템을 다 볼 수 있는 메인화면이 없는 것 같아서 좀 고민이네요^^;
저도 아직 리서치 중이라 다 모르기는 한데 모든 장비를 한꺼번에 보는 것은 Granafa에서 대시보드를 따로 만들면 될것 같습니다. 제가 Cacti를 안써봐서 잘못 이해했을수도 있지만요.