

기본적인 모델링
MongoDB는 join을 할 수 없기 때문에 기본적으로 RDBMS처럼 정규화를 하면 안되며 보통 모델링에서 최상위 객체마다 하나의 컬렉션을 갖는 형태가 됩니다.
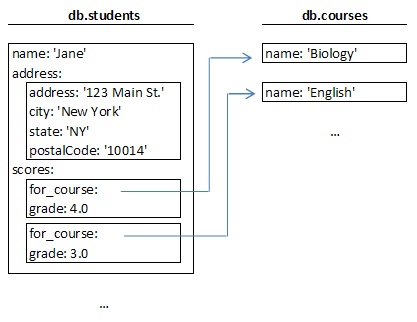
from MongoDB Refernce
위의 다이어그램에서 students, courses의 2개 컬렉션이 존재하는데 students는 address 도큐먼트와 courses 컬렉션을 참조하는 score 도큐먼트를 가지고 있습니다. 반면 RDMBS라면 score는 보통 students의 키를 FK로 가지는 별도의 테이블로 디자인하는게 일반적입니다.
내장(Embed)할 것인가? 참조(Reference)할 것인가?
스키마 디자인에서 "이 객체가 자신만의 컬렉션을 가질 것인가? 다른 컬렉션안에 내장되어야 하는가?"를 결정하는 것이 중요합니다. 일반적인 RDBMS에서는 정규화를 통해서 테이블을 분리하지만 MongoDB에서는 객체를 내장할 경우 디스크에서 같은 곳에 위치하기 때문에 더 효율적입니다. 그래서 오히려 "왜 이 객체를 내장하지 않는가?"하는 관점으로 접근해야 합니다.
student.address.city에 접근한다고 하였을 때 address가 내장객체라면 빠르게 접근할 수 있으며 student가 메모리상에 있다면 address도 메모리에 올라와 있습니다. 반면 student.scores[0].for_corse.name 에 접근한다면 (메모리에 있지 않은 이상) 추가적인 쿼리를 해야 합니다. 각 참조에 대한 탐색은 디비에 대한 쿼리입니다. 보통 컬렉션은 _id로 인덱싱되기 때문에 쿼리는 충분이 빠를 수 있지만 많은 양에 데이터가 반복된다면 참조에 대한 쿼리는 아주 느릴 것입니다. 참조하는 방법은 Simple Manual References, DBRef의 2가지 방법이 일반적입니다.
Simple Manual References
Simple Manual References는 수동으로 코딩된 참조를 의미하며 _id를 다른 문서에 저장합니다.
// 임의로 블로그글을 하나 가져옵니다:
p = db.postings.findOne();
{
"_id" : ObjectId("4b866f08234ae01d21d89604"),
"author" : "jim",
"title" : "Brewing Methods"
}
// 블로그글 p의 작성자에 대한 추가정보를 가져옵니다
a = db.users.findOne( { _id : p.author } )
{ "_id" : "jim", "email" : "jim@gmail.com" }
// 반대로 작성자에 대한 블로그글을 모두 가져옵니다.
db.postings.find( {author : a._id } )
DBRef
DBRef는 문서간에 참조를 하는 표준스펙이며 대부분의 드라이버가 지원합니다. DBRef는 디비내의 다른 것으로의 참조인데 object id처럼 컬렉션의 이름을 포함하며 컬렉션이 다른 도큐먼트로 변경될 수 있다면 DBRef를 사용하는 것이 좋지만 항상 같은 컬렉션을 참조한다면 Manual References가 더 효율적입니다. 또한 DBRef는 표준내장객체(JSON/BSON) 입니다.
{ $ref : <collname>, $id : <idvalue>[, $db : <dbname>] }
DBRef 참조를 위한 문법입니다. <collname>은 참조된 컬렉션명이고(디비명은 적지 않습니다.) <idvalue>는 참조된 객체의 _id필드의 값입니다. $db 부분은 옵션적인 부분이며(아직 대부분의 드라이버에서 지원하지 않습니다.) 다른 디비로의 문서를 참조하도록 합니다.) DBRef를 사용할 때는 문법과 동일한 순서로 적어주어야 합니다. (과거의 BSON DBRef는 더이상 사용하지 않습니다.)
일반적인 규칙
- First Class 객체가 최상위 레벨이면 자신만의 컬렉션을 갖습니다.
- 아이템의 세부사항들은 내장합니다.
- 한 객체에 "포함"관계로 모델링된 객체들은 내장합니다.
- 다대다(Many to Many)관계는 보통 참조합니다.
- 객체가 면개 안되는 컬렉션들은 전체 컬렉션을 빠르게 캐쉬할 수 있도록 분리합니다.
- 내장 객체는 컬렉션에서 "최상위 레벨"객체보다 참조하기 어렵기 때문에 내장객체로의 DBRef를 가질 수 없습니다.
- 내장 객체에 대한 시스템 레벨의 뷰를 얻는 것은 어렵습니다. 예를 들어 Scores가 내장되지 않았다면 상위 100명의 점수를 쿼리하는 것은 쉽습니다.
- 내장하기에 양이 크다면(MB이상) 단일객체의 사이즈 제한에 걸릴것입니다.
- 성능이슈가 있으면 내장합니다.
- 내장문서(Embedded)는 빠르게 쿼리할 수 있으며 부모와 항상 함께 나타납니다.
- 내장되면서 중첩된(Nested) 문서는 복잡한 계층화를 나타내기에 좋고 동일하게 부모와 항상 함께 나타나지만 내부문서에 질의할 때 특정한 레벨에만 하는 것은 쉽지 않습니다.
- 정규화를 하면 유연성을 가질수 있습니다.
일반적인 스키마 디자인은 간단한 스키마에서 시작해서 데이터를 쿼리해보변서 점점 발전시켜 나가는 형태를 취합니다. 반복적인 개발은 MongoDB에서는 어렵지 않습니다.
유즈케이스
이제 몇가지의 유즈케이스를 보겠습니다.
Customer / Order / Order Line-Item
orders와 customers는 컬렉션이어야 합니다. line-items는 order객체에 내장된 line-items의 배열이 되어야 합니다.
블로깅 시스템
posts는 컬렉션이 되어야 합니다. post author는 분리된 컬렉션이거나 이메일주소만 있다면 posts내에 간단한 필드가 됩니다. comments는 성능을 위해서 post내의 내장객체가 되어야 합니다.
1 대 다 관계
배열이나 배열키를 내장할 경우 배열의 서브셋을 리턴하는 slice를 사용합니다. 하지만 모든 문서에서 마지막 커멘트를 찾는 것은 쉽지 않습니다. 트리를 내장할 경우 단일 문서의 형태가 되며 자연스럽지만 쿼리하기가 어렵습니다. 2개의 컬렉션으로 정규화를 할 경우 가장 유연하지만 더 많은 쿼리가 필요합니다.
Index 선택
스키마 디자인의 두번째 관점은 인덱스 선택입니다. 일반적인 규칙에 따라 관계형 디비에서 인덱스하기 원하는 곳에 MongoDB에서도 인덱스 하면 됩니다.
- _id 필드는 자동적으로 인덱스됩니다.
- 찾고자 하는 키에 대한 필드는 인덱스합니다.
- 보통 정렬하는 필드는 인덱스합니다.
MongoDB 프로파일링 기능은 누락된 인덱스에 대한 유용한 정보를 줍니다.
인덱스를 추가하는 것은 컬렉션에 쓰기(Write)를 느리게 하지만 읽기(Read)는 괜찮습니다. 읽기 대 쓰기의 비율이 높은 컬렉션에 많은 인덱스를 사용합니다.(스토리지의 과잉문제는 신경안쓴다고 가정합니다.) 읽기보다 쓰기가 많은 컬렉션에 대해서는 인덱스는 아주 비용이 큽니다.
참고문서
[Schema Design]
[Database References]
[MongoDB Schema Design]
[MongoDB schema design basics]

몽고간장!!
인덱스, 컬렉션, 읽기 쓰기, NoSQL!!
전 공부해야할 게 참 많군요!!
잘 봤습니다. 조만간 몽고DB도 공부를...
공부할게 너무 많아요 ㅠㅠ
좋은정보 감사히 잘 읽었습니다. ^^
예 감사합니다. ^^
안녕하세요 ~ MongoDB로 DB 개념을 처음 공부하고 있는데요.
설명해주신 글 보고 많이 배우네요.
내용을 보다가 궁금한 부분이 있는데요.
특정 사용자의 프로필이 존재하고, 그 사용자가 쓴 글과 그 글에 달린 리플을 갖고 있는 db를 만들어보려고 하는데요.
검색해보니 위에 써주신 것 처럼 상위 컬렉션의 키 값을 하위 컬렉션의 _id 값 같은 키에 저장해서(사용자 이름, 이메일 등)을 연결시키는 방법과 embeded 하는 방식이 있는것 같은데, embeded하는 방법에 대해 하나만 질문드려도 될까요?
user 컬렉션 안에 post 컬렉션을 넣은 형태로 모델링해서 포스트 값을 계속 누적시키고 싶은데요. 모델은 만들었는데 누적을 어떻게 시켜야 될지 감이 잘 안오네요 ..
모델은 아래처럼 만들었고, user 컬렉션안에 post 컬렉션을 overwrite가 아닌 새 값을 추가할려면 어떤 식으로 만들어야 하는 건가요?
{
name : String,
address : String,
post : [{
tag : String,
title : String,
author : String,
body : String
}]
}
스키마 말고 값을 추가하는 쿼리를 말슴하시는 건가요?
db.user.update(
{ name: "SOMETHING" },
{ $push: { post: {} } }
)
제가 지금 테스트는 못해봤는데 이런식으로 하시면 될겁니다. http://docs.mongodb.org/manual/reference/operator/update/push/ 여기를 참고하시면 됩니다. 그리고 경험상이나 사람들이 말하는걸로도 그렇고 시간이 지난에 따라 지속적으로 증가하는 데이터를 임베드로 했을 경우에는 나중에 골치아픈 상황이 발생할 여지가 좀 있습니다.
말씀하신대로 해보니 제가 원하던 형태로 값이 들어가네요 ~ 답글 감사드립니다.
그리고 임베드 형태가 나중에 문제의 여지가 있다면 위 강좌에서 써주신 Simple Manual References 와 같은 형태로 다른 컬렉션을 참조하는 형태로 만드는게 좋을 것 같다는 말씀이신가요?
MongoDB에서 한 도큐먼트는 용량제한이 있습니다.(버전이 올라가면서 늘고 있긴 한데 제가 마지막에 확인했을 때는 4MB였습니다.)
임베드해도 4MB를 넘지않는다면 상관없지만 지속적으로 느는 값인 경우에는 시간이 지남에 따라 한 도큐먼트가 4MB를 넘으면 문제의 소지가 생길 수 있다는 말씀을 드린겁니다.
스키마 디자인의 답은 없지만 임베드와 레퍼런스는 쿼리를 날릴때 어떻게 조인해서 가져오는 경우가 많은지와 데이터의 증가량이 얼마나 될 것인지를 고려하셔야 할겁니다.
아 ~ 그런 이유 때문에 데이터가 증가하는 경우엔 임베드 타입을 지양하는 거였군요 .. 감사합니다 아웃사이더님 덕분에 많이 배웁니다 ^-^
안녕하세요.
아웃사이더님 블로그에서 정말 많이 배우고 있습니다.
이번에 몽고 디비를 써보려고 하는데요. RDB만 써오던 터라 적응이 쉽지 않습니다;;;
그중에서 답답한게 RDB의 경우 저장되 있는 데이터들을 조회해보며 데이터들을 살펴볼 수 있는데요,
몽고의경우 일단 데이터량이 많아지면 불가능한 수준이 되어버리네요;;
nosql 디비들은 이런부분에서는 어떻게 해결이 가능할까요??
디비에 저장되어있는 내용들을 잘 살펴볼 수 있는 방법이 없을까요?
저도 최근에는 MongoDB를 쓸 일이 없어서 최근 도구들은 모릅니다만 GUI 프로그램을 써서 보통 해결했습니다. MongoDB 사이트에 가시면 GUI 클라이언트 들이 많이 있고 커맨드라인에서라면 JSON 이므로 복사해서 JSON 포맷팅을 해서 보곤 했습니다.